


OVERVIEW
As software development advanced, software became better, but so did the demands. The tech industry has gone from deploying to production once in 6 months to deploying 6 times daily. With Agile development methodologies leading the way, software development has advanced at lightning speeds, but there’s always a catch.
“It works on my machine” is a common problem when it comes to software development and testing. Simply put, code and tests written on the developers’ local machines sometimes fail to execute on the machines of testers, fellow developers, or even in production, hampering the software development and testing.
As businesses demanded shipping features faster and reduced time to market, tech teams needed now more than ever to find solutions to the problem of running code consistently across the team and environments.
For context, companies like Amazon, Google, and Netflix deploy to production 1000s of time per day (aggregated over the 100s of services that comprise their production environment). While most companies don’t need to deploy at the rate of these tech giants, deploying once or twice per week is now the new normal. And to achieve this deployment rate, there is less and less scope for team members to say, “It doesn’t work on my machine.”
Docker is a platform that allows developers to create and manage applications in containers, which are lightweight and portable environments. With Docker, we can quickly set up and test applications in isolated environments without worrying about compatibility issues. These containers can be easily shared with others and deployed to different environments, making it an efficient way to manage applications at scale.
Not only does Docker solve the puzzle of running software consistently and at scale, but it also provides the necessary means to set up at scale, high quality, high speed, and resilient automated testing. Since the testing team no longer has to worry about setting up code to run locally, the time saved can be invested in writing better end-to-end automation tests, which ensures high-quality software delivery by catching defects early.
Playwright, a library for automated end-to-end browser testing, and Docker, a platform for running applications in containers, provide a powerful solution for developers looking to streamline their testing process. By combining Playwright and Docker, developers can confidently create, test, and deploy their applications, knowing they will run consistently on any machine.
In this Playwright Docker tutorial, we will dive deep into how Playwright and Docker can be used together. When paired together, it can simplify browser testing and improve the reliability and speed of test automation. It can also reduce the time and resources required for testing complex web applications.
Introduction To Docker
Fun Fact !!! The story of Docker can be traced back to the shipping industry and the development of standardized shipping containers in the mid-20th century. Before standardized containers, the cargo was loaded and unloaded by hand, making shipping slow and inefficient.
But with the introduction of standardized containers, it became possible to load and unload cargo using cranes and other machinery, reducing shipping times and costs. This revolutionized the shipping industry, making it possible to move goods more quickly and efficiently than ever before.
On similar lines, Docker revolutionized the world of software development by introducing a standardized, container-based approach to packaging, distributing, and running applications.
Like shipping containers, Docker containers enable developers to move applications quickly and efficiently between different environments, from development to testing to production, making it easier to develop and deploy software at scale.
What Problem Does Docker Solve?
Before implementing end-to-end testing using Playwright Docker, it’s important to understand what problem Docker solves. Let’s now understand them.
Isolated Execution Environments
With software development becoming accessible to anyone with a laptop and an Internet connection, the differentiating factor now is a shorter time to market and faster feature shipping. And to achieve this, it’s important to provide isolated yet consistent execution for teams.
This is where Docker comes in. Docker is a powerful containerization platform that allows developers to package their applications and dependencies into a portable container that can be easily deployed across different environments. It eliminates the challenges of testing across different environments, ensuring that code runs consistently across all machines.
Streamlining Testing
Docker has become an essential tool for software testing. It provides a way to streamline the application testing process, eliminating the need for complex installation procedures and compatibility issues.
It also enables developers to easily spin up multiple instances of an application in different environments, making it easier to identify and fix bugs before deployment.
Scaling With Reliability And Consistency
Not only does Docker solve consistency issues, but it solves them at scale. Docker orchestration is the process of managing, deploying, and scaling Docker containers. With orchestration tools like Kubernetes, Docker Swarm, and Amazon ECS, we can easily manage many containers and automatically scale them up or down, depending on demand.
This solves the scaling issue that arises when we need to handle a sudden increase in traffic or workload. With Docker orchestration, we can ensure that the containers are always running at optimal capacity, providing a seamless and efficient user experience.
Faster Feature Shipping
In the competitive world of software development, time-to-market and faster feature shipping can be the differentiating factor. Docker’s ability to package applications and dependencies into portable containers enables developers to ship features faster.
By providing consistent and isolated code execution environments. This leads to increased efficiency and faster time-to-market.
Convert your data effortlessly with our CSV to XML tool! Try it now
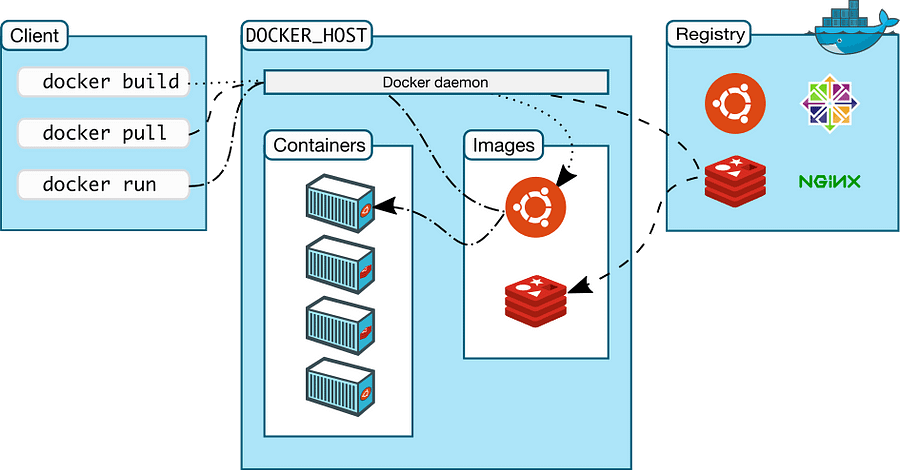
Docker Architecture
Docker consists of a client-server architecture, where the Docker client communicates with the Docker daemon to build, run, and manage containers.
Before we proceed with the installation and writing of tests, let’s first understand the Docker Architecture.
Docker Client
The Docker client (docker) is the primary way many Docker users interact with Docker. When we use commands such as docker run, the client sends these commands to dockerd, which carries them out.
The Docker command uses the Docker API. The Docker client can communicate with more than one daemon.
Docker Host
Docker Host refers to a physical or virtual machine running the Docker engine. The Docker host provides the infrastructure needed to run Docker containers, such as the operating system, storage, networking, and other resources.
The Docker daemon runs on the host machine and manages container images, networks, and storage volumes.
Docker Registry
Docker Registry is a central storage for Docker images. Docker Hub is the preferred registry for Docker, but it’s entirely possible to have your private registry.
Whenever we fire docker pull or push commands, the images are retrieved or stored from the Docker registry.
Docker Objects
Working with Docker involves creating and using images, containers, networks, and volumes. It’s essential to understand these before we proceed.
Docker Images
Docker images are read-only templates that contain everything needed to run an application, including the application code, runtime environment, libraries, and dependencies. Images are built using a Dockerfile, which defines the components and configuration of the application.
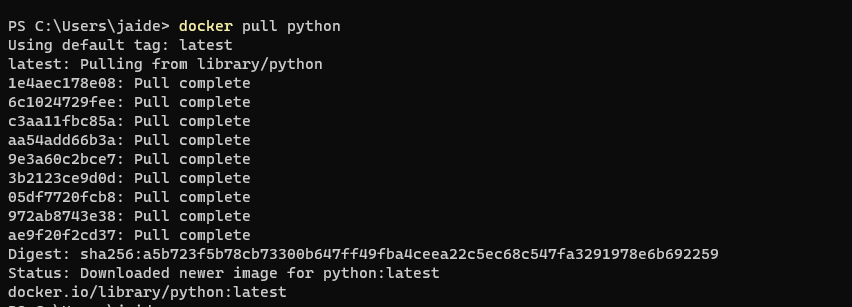
Images are stored in a registry and can be easily shared and reused across different environments. Pre-built images can also be downloaded from Docker Hub using the docker pull command. A sample screenshot showing the download of the Python Docker image is below.
Docker Containers
Docker containers are lightweight, standalone, and executable packages containing an application and all its dependencies (e.g., binaries, packages, libraries, etc.). Containers are created from images and run in a loosely isolated environment, providing isolation and security for the application.
Containers can be easily started, stopped, and managed. They are also designed to be ephemeral, with no persistent state.
Transform YAML to JSON seamlessly using our online converter! Get started today!
Docker Networking
Docker networking enables containers to communicate with each other and the outside world, providing connectivity and flexibility for containerized applications. Containers can be connected to different networks, including default, custom, and overlay networks, depending on applications.
Docker also provides various networking tools and plugins, including DNS, load balancing, and software-defined networking (SDN).
Docker Storage
Docker storage offers a range of options for managing and persisting data in containers, including volumes, bind mounts, and tmpfs mounts. Volumes are the preferred way to manage data in Docker, providing persistent storage that can be shared between containers and preserved even when a container is deleted.
Docker also offers a range of storage plugins and drivers, including support for storage systems like Network File System(NFS), Amazon Elastic Block Store(EBS), and more.
A Quick Word About Open Container Initiative (OCI).
As containerization gained popularity and its adoption started to increase, in 2015, a group of industry leaders, including Docker, CoreOS, and Red Hat, came together to form the OCI, or the Open Container Initiative.
At the time, the container ecosystem was fragmented, with different vendors and platforms offering their proprietary container formats and runtimes. This made it difficult for developers to move containerized applications between different environments and added complexity to the containerization process.
The goal of OCI is to standardize how containers are built and run across different platforms, making it easier to move containerized applications between different environments.
How To Install Docker On Windows?
For this Playwright Docker tutorial, we are using a Windows machine for the demonstration. Some of the below-mentioned steps might not be applicable when using Docker on macOS.
Here are the quick steps for installing Docker on Windows:
Enabling WSL2, Hyper-V, and Virtualization
Based on the OS, Docker allows us the choice of the virtualization backend, i.e., we can either choose WSL2 (Windows Subsystem For Linux) or Hyper-V. Docker is designed to run on Linux-based machines. Hence, it runs without any additional macOS installation but needs the WSL installation on Windows.
Hyper-V is a full-fledged virtualization technology that allows us to create and manage virtual machines on a Windows system, while WSL2 is a lightweight virtualization technology that enables running a Linux distribution natively on a Windows system, primarily for developers who want to use Linux tools and applications on a Windows system.
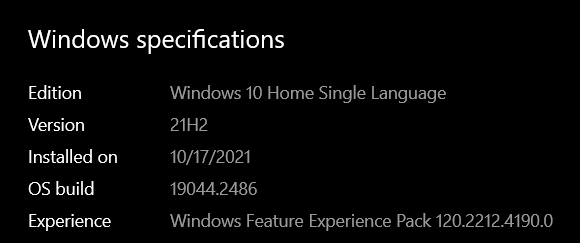
With that out of the way, let’s see the Windows version we are running on. To check the version, navigate to Windows Explorer, right-click on PC, and click Properties. We are running a Windows 10 Home Edition as seen from the image below:
Based on the Windows version below is the choice of the virtualization backends.
WLS2 Backend
Windows 11 64-bit: Home or Pro version 21H2 or higher, or Enterprise or Education version 21H2 or higher.
Windows 10 64-bit: Home or Pro 21H1 (build 19043) or higher, or Enterprise or Education 20H2 (build 19042) or higher.
Hyper-V Backend
Windows 11 64-bit: Pro version 21H2 or higher, or Enterprise or Education version 21H2 or higher.
Windows 10 64-bit: Pro 21H1 (build 19043) or higher, or Enterprise or Education 20H2 (build 19042) or higher.
The process to enable WSL2, Hyper-V, and Virtualization is similar. Open the Run (Windows + r) and type optionalfeatures.exe
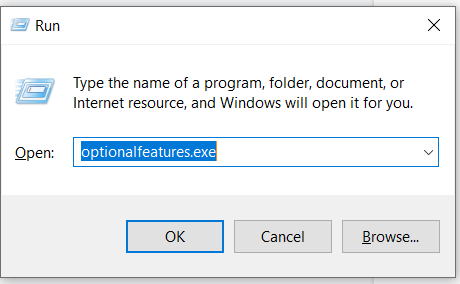
On the subsequent screen that opens, based on the OS version, enable either Virtual Machine Platform and WSL2 or Hyper-V
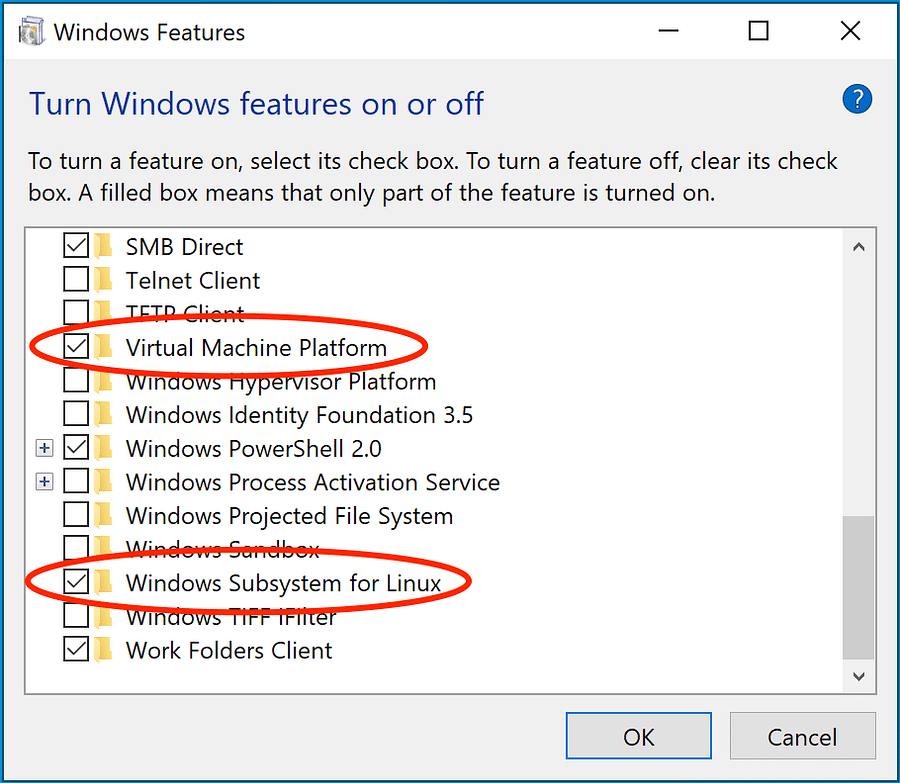
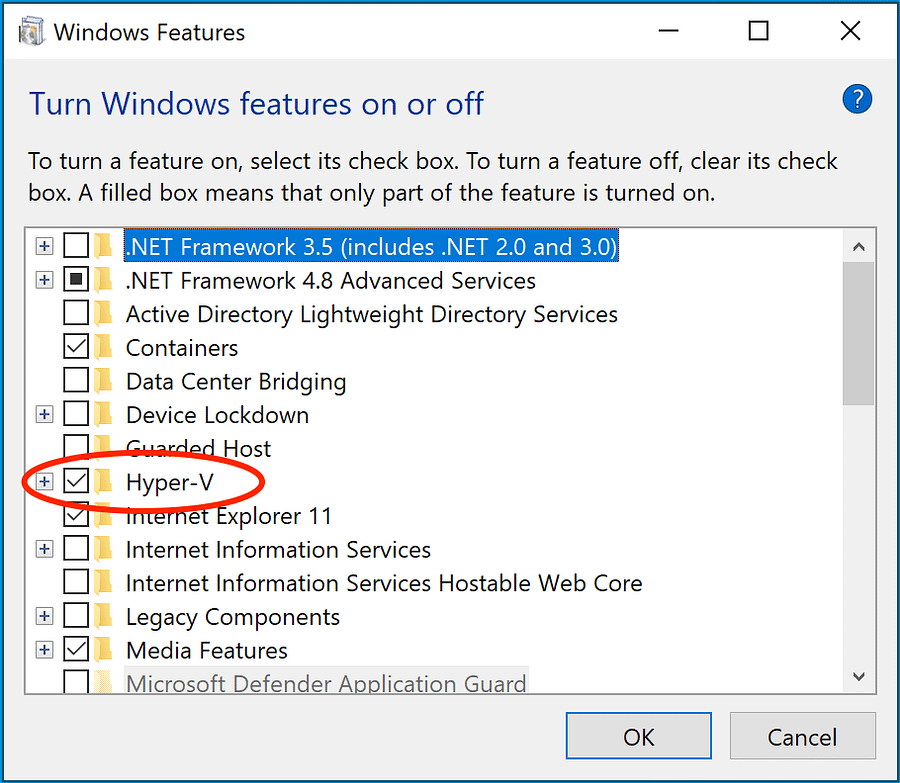
This completes the prerequisites of WSL2 and the Hyper-V setup needed to install Docker. In the next step of this Playwright Docker tutorial, we proceed to install Docker Desktop, the application necessary for creating and managing Docker containers.
Installing Docker Desktop
Docker Desktop is an application for creating and managing Docker containers on the computer. It provides a graphical user interface and command-line interface for working with containers. Let’s proceed with downloading Docker for windows Docker for windows. After downloading, follow the step-by-step installation guide.
- The downloaded installation package will be verified first.
- Once the package verification is completed unpacking and installation will start.
- If everything goes well, we should see the following Installation succeeded prompt.
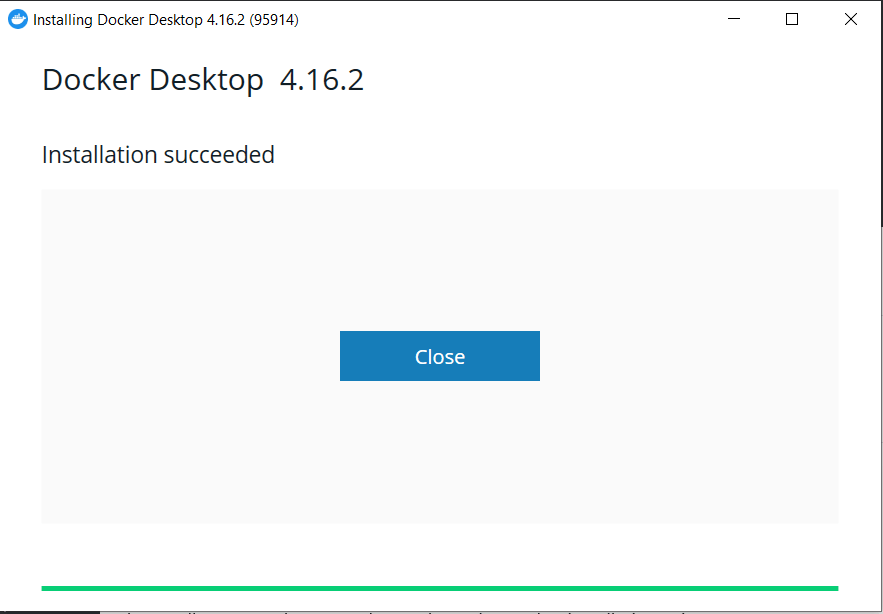
To use the Docker Desktop, we must sign up on Docker Hub and create an account. After signing up, start the Docker Desktop from the Windows start menu. Upon starting it, we need to log in using the account we created on Docker Hub.
Once logged in, Docker will attempt to start, and we should see a screen as shown below:
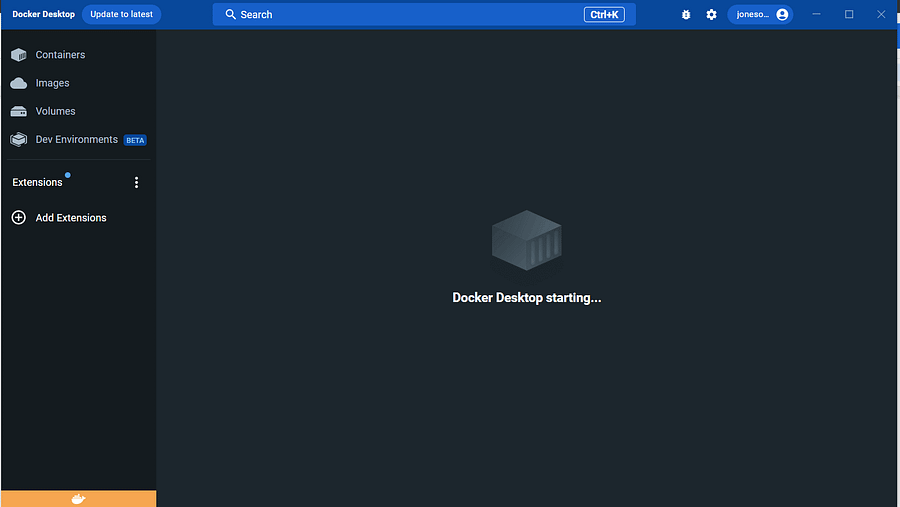
Need to convert HTML to CSV? Our free tool makes it a breeze! Check it out now!
Troubleshooting Tip 💡 WSL1 To WSL2 Upgrade
If the screen freezes at this point, i.e., Docker Desktop starting… prompt doesn’t go away, it’s most probably because the machine does not have the WSL 2. We need to upgrade from WSL1 to WSL2.
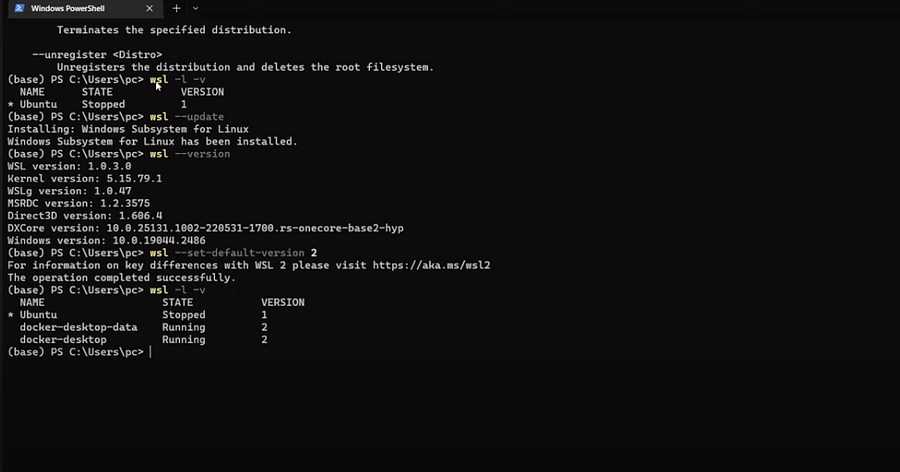
Run the below set of commands in the Windows PowerShell command prompt or the newly launched Windows Terminal as per preference.
wsl -l -v to view the WSL version. We can see WSL version 1 exists, but we need version 2.

wsl — update (to update to version 2).
wsl –set-default-version 2 (to set 2 as the default version).
Once done, run the wsl -l -v command again and restart the Docker desktop.
After completing all the steps mentioned till this point, a successfully running Docker installation will look as shown in the below image.
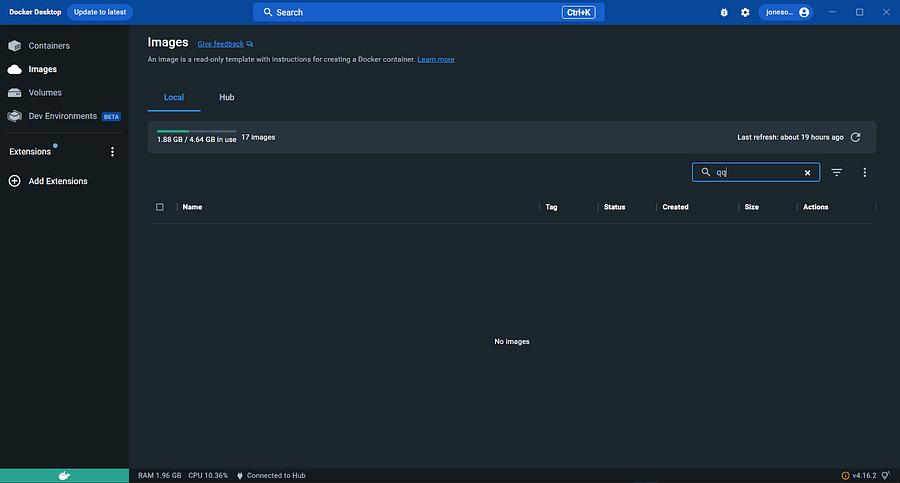
Check the settings, and based on the Windows version, there will be options to select the backend. It defaults to WSL 2 as we are running Windows 10 Home version.
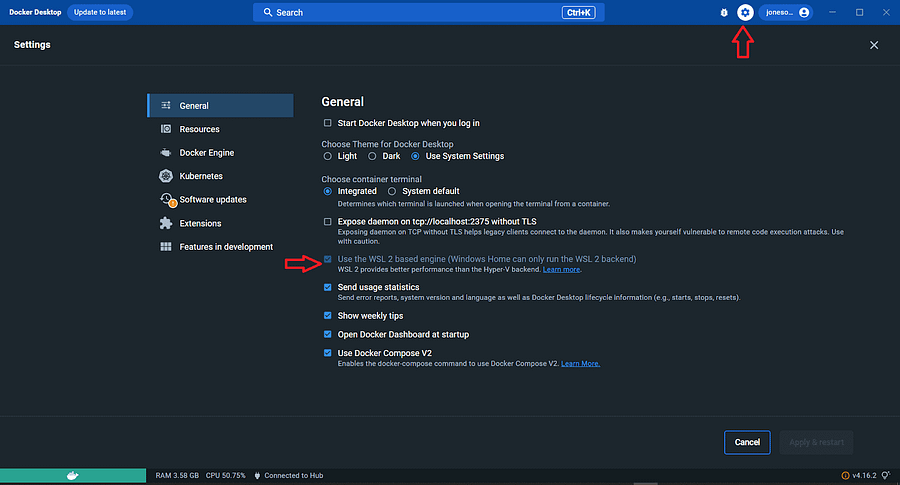
“Streamline your software development and integration process with the LambdaTest Docker integration. Seamlessly incorporate software applications into your current workflows”
Brief Introduction To Playwright
Playwright is an end-to-end web testing and browser automation framework. It is immensely helpful for writing test cases for both modern, i.e., dynamic and static web apps.
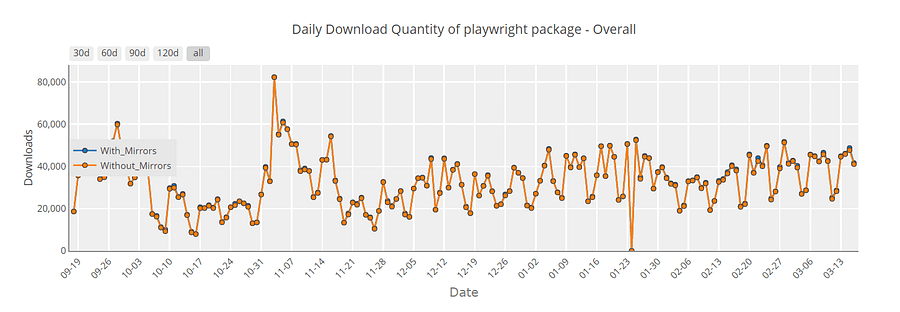
At the time of writing this Playwright Docker tutorial, the latest stable version of Playwright is 1.28.0, and Playwright is now consistently hitting the > 20K download per day mark, as seen from PyPi Stats.
Below are the download trends of Playwright compared to a popular alternative, Selenium, taken from Pip Trends.
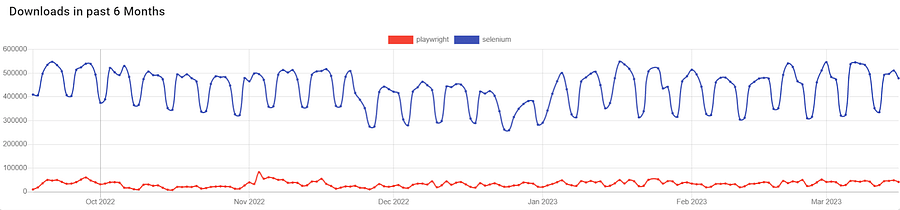
A key consideration to make when using any language, tool, or framework is the ease of its use.
Key features of Playwright
Playwright supports all major browsers, including Chromium, Firefox, Microsoft Edge, and WebKit
Playwright’s APIs are available in various programming languages, such as Python, Java, JavaScript, TypeScript, and .NET
Playwright is a cross-platform tool that works seamlessly on Windows, macOS, and Linux in both headless and non-headless modes
Playwright’s auto-wait feature eliminates the need for artificial timeouts, making tests more robust and less prone to errors.
Playwright includes a codegen tool that helps locate elements with ease.
Playwright Locators provide easy APIs for finding elements on websites.
In the next section of this Playwright Docker tutorial, we will learn how to set up Playwright for Python.
Setting Up Playwright For Python
Playwright is a powerful tool that allows you to automate browser tasks such as filling out forms, clicking buttons, and scraping data from web pages. It supports multiple programming languages, including Python. In this Playwright Docker tutorial, we will go through the steps to set up Playwright for Python so you can start automating your browser tasks.
First, create a dedicated folder for the project called Docker Playwright (This step is not mandatory but is good practice).
Inside the folder we just created, use the built-in venv module to create a virtual environment named docker playwright.

Activate the virtual environment by calling the activate script.
Install the Playwright module using pip install pytest-playwright.
Lastly, install the required browsers using playwright install.
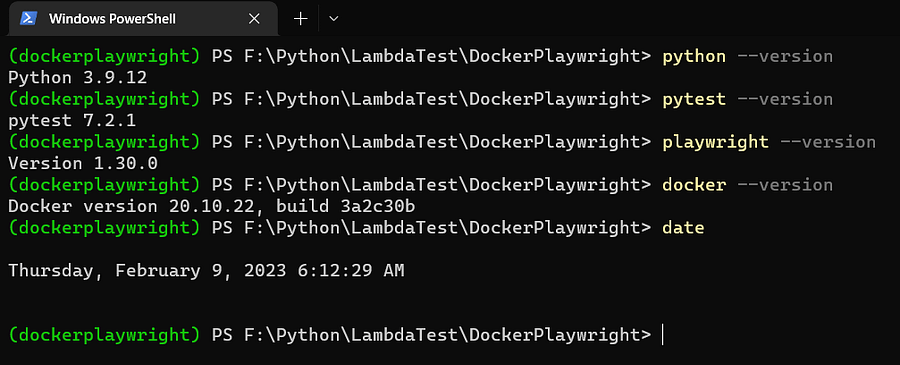
All the tests in this Playwright Docker tutorial have been thoroughly tested on the following versions.
Docker 20.10.22, build 3a2c30b
Python 3.9.12
Pytest 7.2.1
Playwright 1.30.0
Easily convert ASCII to Binary with our online tool! Give it a go!
Project Structure
We will be using the LambdaTest eCommerce Playground for writing the tests. Before moving to dockerizing them, let’s check each in detail and execute them locally without Docker. We will write a total of 8 tests designed to test various functions across 3 different pages on the test website.
To make the test suite structured, easy to extend, and maintain, we will use the Page Object Model (POM) design pattern to arrange the tests. Here is what the project directory structure looks like.
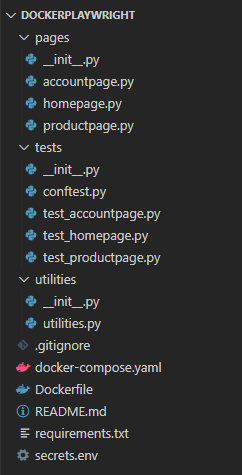
Let’s understand the structure in brief first
The pages folder contains python files for each page. Each file contains a class we want to abstract This structure allows the code to remain organized and increases reusability.
The tests folder contains the test cases which we want to run. These are again segregated based on the page that they will be testing. The name of this folder is in accordance with the pytest requirement.
The utilities folder contains a single utilities.py where we can add all the reusable supporting code.
The docker-compose.yaml contains the code to help build the Docker container effectively in case of a multi-container setup.
The Dockerfile contains the build of the Docker image from the code.
The requirements.txt contains all the Python packages we will need to run the code.
secrets.env is where we abstract the environment variables to control the test runs, browsers, operating systems used, etc.
Implementation (Fixtures & Configuration)
Let us now look at the implementation of the environment file, configuration file, and fixtures file. The environment variables control the test execution environment.
The configuration file contains reusable utilities and the special conftest.py file that allows us to define and share fixtures, hooks, and plugins across multiple test files.
secrets.env
The first supporting file we need to run the code is the secrets.env. This file controls the environment we run the code on, i.e., local or cloud. Username and Access Key of the cloud grid provider. It also controls the Operating system and Browser where the tests will run.

All the reusable code which supports the running of the tests and is called from multiple places within the main script is put in the utilities.py file. The dotenv Python package reads key-value pairs from the .env file and sets them as an environment variable. This is done by calling load_dotenv(‘secrets.env’).
The three lines after that are used to read the environment variables values, i.e., operating system, browser, and the environment, i.e., cloud or local. The tests will be defaulted to run locally.
from playwright.sync_api import Page
from dotenv import load_dotenv
import os
load_dotenv('secrets.env')
platform = os.getenv('PLATFORM')
browser = os.getenv('BROWSER')
run_on = os.getenv("RUN_ON") or 'local'
The set_test_status function is used to set the results of the test execution when running the code on a cloud grid. When running locally, this function does not do anything.
def set_test_status(page: Page, status: str, remark: str):
"""
Function to set stats, title and description of test run on cloud grid
:param page: instance of Playwright browser page
:param status: status of test e.g Pass or Failed
:param remark: additional remark about test status
"""
page.evaluate(
"_ => {}",
"lambdatest_action: {"action": "setTestStatus", "arguments": {"status":"" + status + "", "remark": "" + remark + ""}}"
The capabilities dictionary is used to configure the test environment when running on a cloud grid. The most notable configurations are the Platform, i.e., the Operating system and the browser. Both these are controlled using environment variables defined in secrets.env.
capabilities = {
'browserName': browser,
'browserVersion': 'latest',
'LT:Options': {
'platform': platform,
'build': 'Playwright Docker Demo Build',
'name': f'Playwright Docker Test For {platform} & {browser}',
'user': os.getenv('LT_USERNAME'),
'accessKey': os.getenv('LT_ACCESS_KEY'),
'network': True,
'video': True,
'visual': True,
'console': True,
'tunnel': False, # Add tunnel configuration if testing locally hosted webpage
'tunnelName': '', # Optional
'geoLocation': '', # country code can be fetched from https://www.lambdatest.com/capabilities-generator/
}
}
Pytest fixtures are a powerful feature of the pytest testing framework that allows us to organize and manage the test code in a more efficient and reusable way. Essentially, pytest fixtures are reusable pieces of code that provide data or resources to the test functions.
This can include pre-populating a database with test data, creating and configuring objects that the tests depend on, or mocking external APIs to simulate certain behaviors.
conftest.py is a special file in pytest that allows us to define fixtures and other configuration options that can be shared across multiple tests. This naming convention is mandatory; otherwise, pytest will not be able to locate the fixtures.
By placing conftest.py in the tests directory, we can make the fixtures and configuration options defined in it available to all test functions and modules in that directory and its subdirectories.
Fixtures are defined using the same syntax as a normal function and decorating the function with the @pytest.fixture decorator. Optionally we can also give the fixture a name. In this case, we have given it the name browser because we are using it to return a Playwright browser instance.
import pytest
import os
from playwright.sync_api import sync_playwright
from utilities.utilities import capabilities, run_on
from pages import homepage, accountpage, productpage
import subprocess
import urllib
import json
@pytest.fixture(name="browser")
def playwright_browser():
print(run_on)
if run_on == 'local':
with sync_playwright() as playwright:
browser = playwright.chromium.launch(headless=True)
yield browser
if run_on == 'cloud':
with sync_playwright() as playwright:
playwrightVersion = str(subprocess.getoutput('playwright --version')).strip().split(" ")[1]
capabilities['LT:Options']['playwrightClientVersion'] = playwrightVersion
lt_cdp_url = 'wss://cdp.lambdatest.com/playwright?capabilities=' + urllib.parse.quote(json.dumps(capabilities))
browser = playwright.chromium.connect(lt_cdp_url)
yield browser
The next three fixtures we have defined are for providing a page instance. All three fixtures take in the fixture defined above as input and create a Playwright page instance. Using this Page instance, we initialize the respective Page Object and yield it.
@pytest.fixture
def account_page(browser):
page = browser.new_context().new_page()
account_page = accountpage.AccountPage(page)
yield account_page
@pytest.fixture
def home_page(browser):
page = browser.new_context().new_page()
home_page = homepage.HomePage(page)
yield home_page
@pytest.fixture
def product_page(browser):
page = browser.new_context().new_page()
product_page = productpage.ProductPage(page)
yield product_page
This completes the setup code walkthrough, and we are now ready to see the actual tests.
Want to convert ASCII to Hex? Try our simple online converter now
Implementation (POM & Tests)
The test suite is going to consist of 8 tests in total which test functionality of 3 different pages:
Home page
My account page
Product page
As shown in the project structure, we will create a .py file under pages directory, which represents the class object for each page under test. So, homepage.py will define the code corresponding to the Home page, accountpage.py will define the code corresponding to the My account page, and productpage.py will define the code corresponding to the Product page.
This approach ensures that the code remains organized, is easy to maintain, and also easy to extend for adding more tests in the future.
Test Scenarios (Homepage)
We will write two test scenarios for the Home page, defined below.
The Home page should contain the ‘SEARCH’ button and be visible.
The Home page should contain the ‘My account’ link and URL to navigate to the Account section.
Code Walkthrough (pages/homepage.py)
On inspecting the Home page, we can see that the ‘SEARCH’ has a button role.
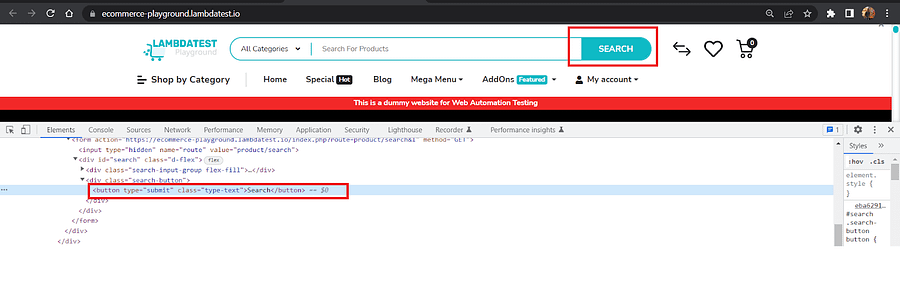
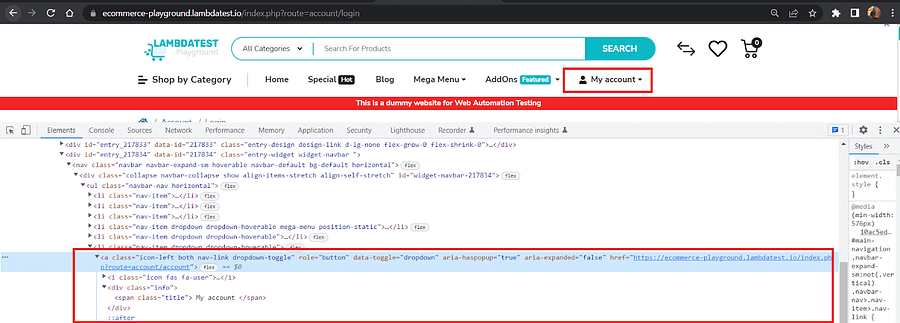
And that ‘My account’ is a link that contains the href attribute.
from playwright.sync_api import expect
from utilities.utilities import set_test_status
class HomePage:
def __init__(self, page):
self.page = page
self.search_button_locator = page.get_by_role(role="button", name="Search")
self.myaccount_link_locator = page.get_by_role(role="link", name="My Account")
Step 1: We define a class HomePage where we will group all the code.
Step 2: The init*.py* method takes an instance of a Playwright page as a parameter, and using that, we define two Playwright locators as instance attributes.
Step 3: Search has a button role with the name ‘Search’ we use the get_by_role() locator to locate it and store it in an instance attribute search_button_locato
Step 4: My account has a link role with the name ‘My Account’ we can again use get_by_role() locator to locate it and store it in an instance attribute myaccount_link_locator
def navigate(self):
self.page.goto("https://ecommerce-playground.lambdatest.io/")
navigate() method defined in the HomePage class calls the goto() method on the Playwright page instance and navigates to the home page URL supplied to it
def search_button(self):
try:
expect(self.search_button_locator).to_be_visible()
set_test_status(self.page, "Passed", "Search button is visible")
except Exception as ex:
set_test_status(self.page, "Failed", "Search button is not visible")
Step 1: The search_button() method then calls the Playwright except() assertion to verify if the element located by search_button_locator is visible
Step 2: The set_test_status() method defined in the utilities.py is called then to inform the cloud grid of the status of the test if running on cloud grid
def myaccount_link(self):
try:
expect(self.myaccount_link_locator).to_have_attribute("href", "https://ecommerce-playground.lambdatest.io/index.php?route=account/account")
set_test_status(self.page, "Passed", "My account link is visible")
except Exception as ex:
set_test_status(self.page, "Failed", "My account link is not visible")
Step 1: The myaccount_link() method then calls the Playwright except() assertion on the instance attribute myaccount_link_locator to expect it to have href attribute with the link for account section. You can learn more about it through this tutorial on Playwright assertions.
Step 2: The set_test_status() method defined in the utilities.py is called to inform the cloud grid of the status of the test if running on the cloud grid.
Code Walkthrough (tests/test_homepage.py)
The class file homepage.py contains all the location and assertion codes. All that remains to write in the test_homepage.py is to call the methods defined by creating an object of the Homepage class. We have abstracted this object creation in the fixture home_page() defined in the conftest.py discussed above.
from playwright.sync_api import expect
from utilities.utilities import set_test_status
from pages.homepage import HomePage
def test_homepage_contains_search_button(browser, home_page):
"""
Test to verify if search button exists on the home page
"""
home_page.navigate()
home_page.search_button()
browser.close()
Step 1: The test_homepage_contains_search_button() takes in browser and home_page fixtures.
Step 2: Using the home_page, we call the navigate() method to open the home page.
Step 3: On the opened homepage, call the search_button() method, which contains the test logic.
def test_homepage_contains_myaccount_link(browser, home_page):
"""
Test to verify if my account link exists on the home page
"""
home_page.navigate()
home_page.myaccount_link()
browser.close()
Step 1: The takes in browser and home_page fixtures.
Step 2: Using the home_page, we call the navigate() method to open the home page.
Step 3: On the opened homepage, call the myaccount_link() method, which contains the test logic.
Step 4: We close the browser by calling browser.close() to ensure the release of resources.
Test Scenarios (Account Page)
We will write three test scenarios for the account page defined below.
The Account page should contain a registration link for new customers.
The Account page should contain the Email & Password field in the login form for returning customers.
The Account page should contain the Forgotten Password link.
Code Walkthrough (pages/account.py)
On inspecting the account page, we can see that New Customer Registration has a role link with the name Continue and href attribute to redirect to registration.
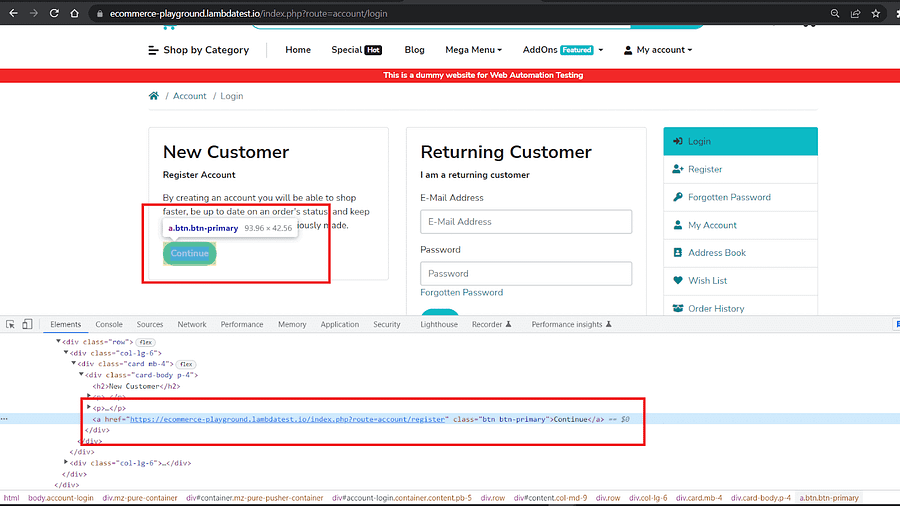
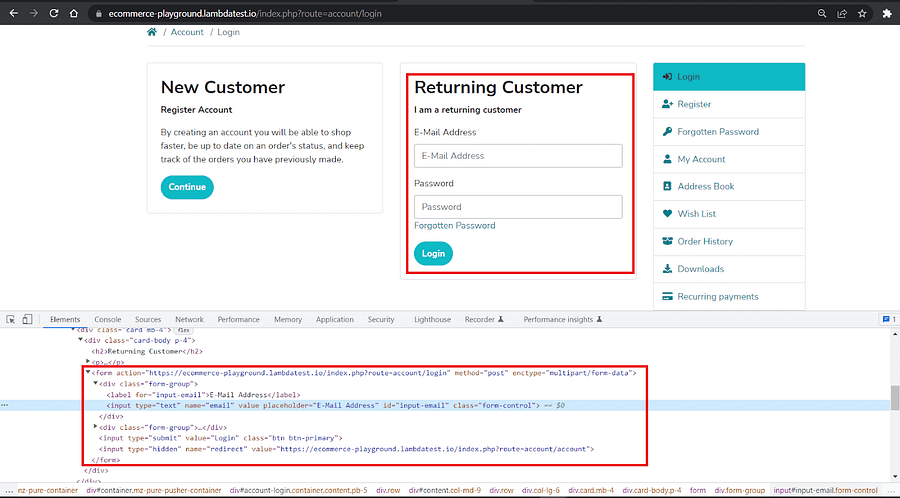
The Returning Customer form has fields for email & password with placeholders ‘E-Mail Address’ and ‘Password’.
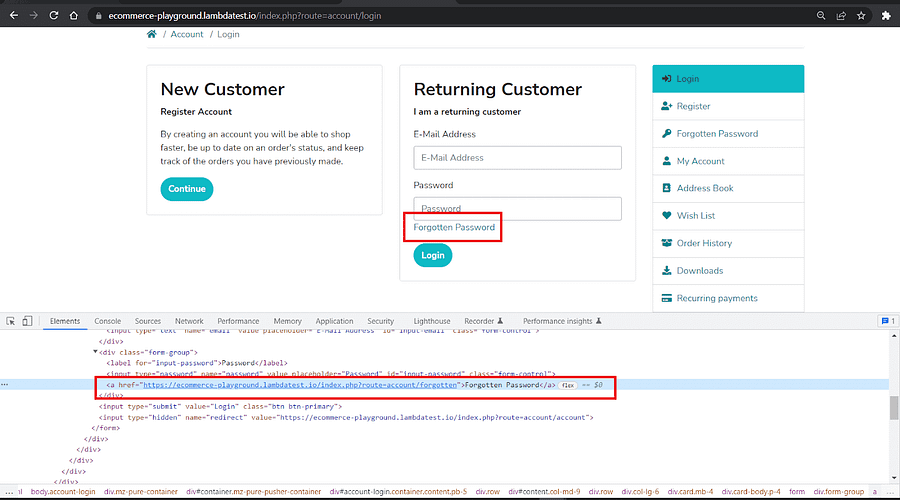
Inspecting the Forgotten Password shows that it has the role link with the href attribute redirecting to the forgotten password.
from playwright.sync_api import expect
from utilities.utilities import set_test_status
class AccountPage:
def __init__(self, page):
self.page = page
self.new_registration_link_locator = page.get_by_role(role="link", name="Continue")
self.email_field_locator = page.get_by_placeholder("E-Mail Address")
self.password_field_locator = page.get_by_placeholder("Password")
self.forgotten_password_link_locator = page.get_by_role(role="link", name="Forgotten Password", exact=True)
Step 1: We define a class AccountPage where we will group all the tests related to the My Account page.
Step 2: The init.py method takes in an instance of a Playwright page as a parameter, and using that, we define four Playwright locators in it as instance attributes.
Step 3: New Registration has a link role with the name ‘Continue’, so we use the get_by_role() Playwright locator to locate it and store it in an instance attribute new_registration_link_locator.
Step 4: Since the login form field email has a placeholder ‘E-Mail Address,’ we use the Playwright locator get_by_placeholder() and store the located element in an instance attribute email_field_locator.
Step 5: The login form field password has a placeholder ‘password’, so we use the Playwright locator get_by_placeholder() and store the located element in an instance attribute password_field_locator.
Step 6: Also, the ‘Forgotten Password’ has a link role, so we can use the get_by_role() Playwright locator and store it in an instance attribute forgotten_password_link_locator.
def navigate(self):
self.page.goto("https://ecommerce-playground.lambdatest.io/index.php?route=account/login")
The navigate() method defined in the AccountPage class calls the goto() method on the Playwright page instance and navigates to the account page URL supplied to it.
def new_registration(self):
try:
expect(self.new_registration_link_locator).to_have_attribute("href", "https://ecommerce-playground.lambdatest.io/index.php?route=account/register")
set_test_status(self.page, "Passed", "Registration link is visible")
except Exception as ex:
set_test_status(self.page, "Failed", "Registration link is not visible")
Step 1: The new_registration() method then calls the Playwright except() assertion on the instance attribute new_registration_link_locator and verifies if it has an href attribute and the link points to the registration endpoint.
Step 2: The set_test_status() method defined in the utilities.py is called to inform the cloud grid of the status of the test if running on the cloud grid.
def login_form(self):
try:
expect(self.email_field_locator).to_be_visible()
expect(self.password_field_locator).to_be_visible()
set_test_status(self.page, "Passed", "Login form contains email & password fields")
except Exception as ex:
set_test_status(self.page, "Failed", "Login form does not contains email & password fields")
Step 1: The login_form() method is where we use the expect() Playwright assertion to verify that the elements located by email_field_locator and password_field_locator are visible.
Step 2: The set_test_status() method defined in the utilities.py is called to inform the cloud grid of the test status if running on the cloud grid.
def forgotten_password(self):
try:
expect(self.forgotten_password_link_locator).to_have_attribute("href","https://ecommerce-playground.lambdatest.io/index.php?route=account/forgotten")
set_test_status(self.page, "Passed", "Forgotten Password link is visible")
except Exception as ex:
set_test_status(self.page, "Passed", "Forgotten Password link is not visible")
Step 1: The forgotten_password() method is where we expect() that the located forgotten_password_link_locator to have an href attribute with the specific link.
Step 2: The set_test_status() method defined in the utilities.py is called to inform the cloud grid of the status of the test if running on the cloud grid.
Code Walkthrough (tests/test_accountpage.py)
The class file accountpage.py contains all the element locations and assertion code. All that remains to write in the test_accountpage.py is to call the methods defined by creating objects of the class AccountPage.
We have abstracted this object creation in the fixture account_page() defined in the conftest.py discussed above.
from playwright.sync_api import expect
from utilities.utilities import set_test_status
from pages.accountpage import AccountPage
def test_myaccount_page_contains_registration_link(browser, account_page):
"""
Test to verify if new customer registration link exists on account page
"""
account_page.navigate()
account_page.new_registration()
browser.close()
Step 1: The test_myaccount_page_contains_registration_link() takes in browser and account_page fixtures as parameters and using account_page, we call the navigate() method to open the account page.
Step 2: This is followed by calling the new_registration() method, where we assert the registration link to be present.
def test_myaccount_page_contains_login_form_with_email_and_password(browser, account_page):
"""
Test to verify if customer login form exists on account page and contains email and password fields
"""
account_page.navigate()
account_page.login_form()
browser.close()
Step 1: The test_myaccount_page_contains_login_form_with_email_and_password() takes in browser and account_page fixtures as parameters.
Step 2: We use the account_page, which is nothing but an instance of the AccountPage class, to call the navigate() method to open the account page.
Step 3: This is followed by calling the login_form() method, where we assert email & password fields to be visible to be present.
def test_myaccount_page_contains_forgotten_password_link(browser, account_page):
"""
Test to verify if forgotten password link exists on account login page
"""
account_page.navigate()
account_page.forgotten_password()
browser.close()
Step 1: The test_myaccount_page_contains_forgotten_password_link() takes in browser and account_page fixtures as parameters.
Step 2: We use the account_page, which is nothing but an instance of the AccountPage class, to call the navigate() method to open the account page.
Step 3: This is followed by calling the forgotten_password() method, where we assert it to be a link with the href attribute.
Step 4: Close the browser by calling the browser.close() ensures the release of resources.
Test Scenarios (Product Page)
We will write three test scenarios for the product page defined below.
The Product page should contain an ‘Add To Cart’ button.
The Product page should contain a ‘Buy Now’ button.
The Product page should contain a checkout where the option to use coupon code exists.
Code Walkthrough (pages/productpage.py)
Inspection of ‘ADD TO CART’ shows that it has a button role and is named ‘Add to Cart’
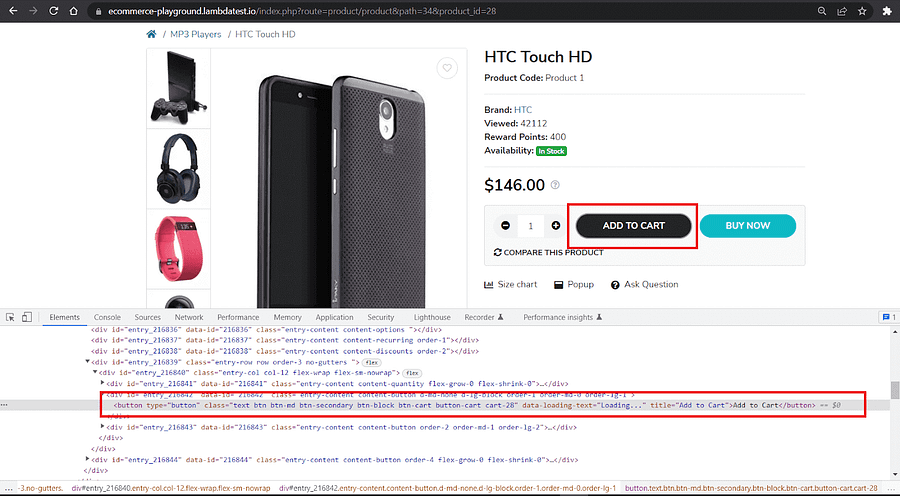
Inspection of ‘BUY NOW’ shows that it has a button role and is named ‘Buy now’.
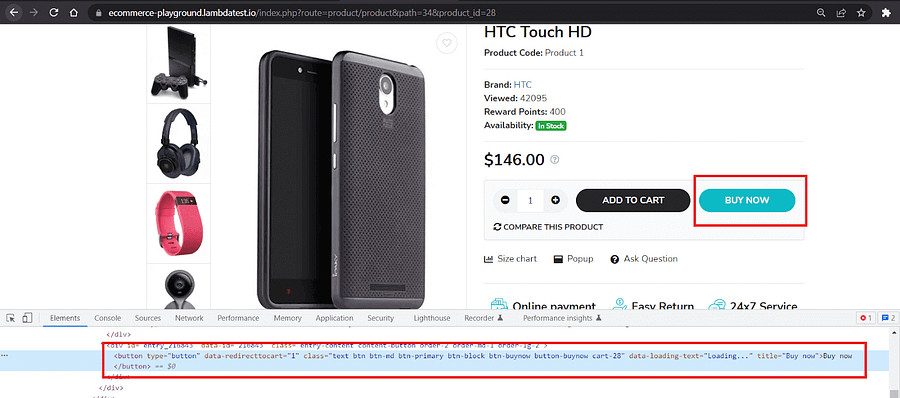
Inspection of the coupon code input field shows that it has a placeholder ‘Enter your coupon here’.
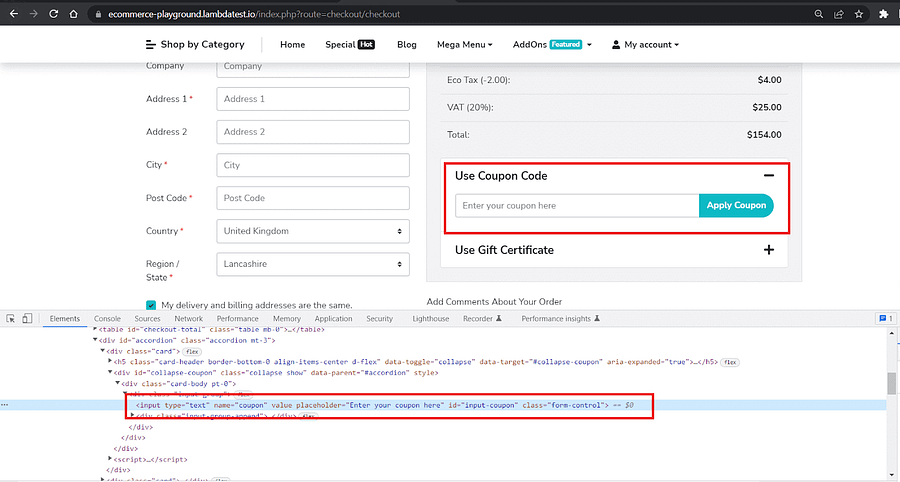
Based on the inspection, we can now write the page object ProductPage which abstracts all details necessary to run the tests.
from playwright.sync_api import expect
from utilities.utilities import set_test_status
import re
class ProductPage:
def __init__(self, page):
self.page = page
self.addtocart_button_locator = page.get_by_role(role="button", name=re.compile("add to cart", re.IGNORECASE))
self.buynow_button_locator = page.get_by_role(role="button", name=re.compile("buy now", re.IGNORECASE))
Step 1: The page object class is called ProductPage since it deals with tests for information on the product.
Step 2: The init*.py* method takes in an instance of a Playwright page as a parameter, and using that, we define two Playwright locators as instance attributes.
def navigate(self):
self.page.goto("https://ecommerce-playground.lambdatest.io/index.php?route=product/product&path=34&product_id=28")
The navigate() method remains the same as previous tests, and the only difference is it takes in a specific product URL.
def add_to_cart(self):
try:
expect(self.addtocart_button_locator).to_be_visible()
set_test_status(self.page, "Passed", "Add To Cart button is visible")
except Exception as ex:
set_test_status(self.page, "Failed", "Add To Cart button is not visible")
Step 1: The add_to_cart() method uses the Playwright expect() construct to assert the element located by the addtocart_button_locator to be visible.
Step 2: The set_test_status() method defined in the utilities.py is called to inform the cloud grid of the test status if running on the cloud grid.
def buy_now(self):
try:
expect(self.buynow_button_locator).to_be_visible()
set_test_status(self.page, "Passed", "Buy Now button is visible")
except Exception as ex:
set_test_status(self.page, "Failed", "Buy Now button is visible")
Step 1: The buy_now() method is similar to add_to_cart() the only difference being it verifies the element located by buynow_button_locator to be visible.
Step 2: The set_test_status() method defined in the utilities.py is called to inform the cloud grid of the test status.
def checkout_product(self):
try:
# Add a product to cart first & click checkout
self.page.goto("https://ecommerce-playground.lambdatest.io/")
self.page.get_by_role("button", name="Shop by Category").click()
self.page.get_by_role("link", name="MP3 Players").click()
self.page.get_by_role("link", name="HTC Touch HD HTC Touch HD HTC Touch HD HTC Touch HD").click()
self.page.get_by_role("button", name="Add to Cart").click()
self.page.get_by_role("link", name="Checkout ").click()
# Perform the test on the checkout
coupon_code_locator = self.page.get_by_placeholder("Enter your coupon here")
expect(coupon_code_locator).to_be_visible()
set_test_status(self.page, "Passed", "Use Coupon Code option is visible")
except Exception as ex:
set_test_status(self.page, "Failed", "Use Coupon Code option is visible")
Step 1: The checkout_product() method differs from the other methods we have written so far in the sense that we first need to add a product to the cart and checkout.
Step 2: We start this method by navigating to the homepage of the test website using page.goto().
Step 3: Once on the homepage, we locate the product, and on the located product, use the Playwright click() action to add it to the cart.
Step 4: On adding to the cart, we again use the Playwright click() action to check out the product.
Step 5: On checkout, we create a locator using the get_by_placeholder() Playwright locator to locate the coupon code text box and store it in a variable coupon_code_locator.
Step 6: We then expect() the element located by coupon_code_locator to_be_visible().
Step 7: The set_test_status() method defined in the utilities.py is called to inform the cloud grid of the test status if running on the cloud grid.
Code Walkthrough (tests/test_productpage.py)
The class file productpage.py contains all of the element location and assertion code. All that remains to write in the test_productpage.py is to call the methods defined by creating objects of the class ProductPage.
We have abstracted this object creation in the fixture product_page() defined in the conftest.py discussed above.
from playwright.sync_api import expect
from utilities.utilities import set_test_status
from pages.productpage import ProductPage
def test_product_page_contains_addtocart_button(browser, product_page):
"""
Test to verify if product page has "add to cart" button
"""
product_page.navigate()
product_page.add_to_cart()
browser.close()
Step 1: The test_product_page_contains_addtocart_button() calls the navigate() method using the product_page object to open the product page.
Step 2: Calling the add_to_cart() then executes the expect() assertion written in it.
def test_product_page_contains_buynow_button(browser, product_page):
"""
Test to verify if product page has "buy now" button
"""
product_page.navigate()
product_page.buy_now()
browser.close()
Step 1: The test_product_page_contains_buynow_button() calls the navigate() method using the product_page object to open the product page.
Step 2: Calling the buy_now() then executes the expect() assertion written in it.
def test_checkout_page_contains_use_couponcode_option(browser, product_page):
"""
Test to verify if product page has "use coupon code" option is available on checkout page
"""
product_page.checkout_product()
browser.close()
The test_checkout_page_contains_use_couponcode_option() calls directly the checkout_product() method where we execute the expect() assertion written in it.
Execution:
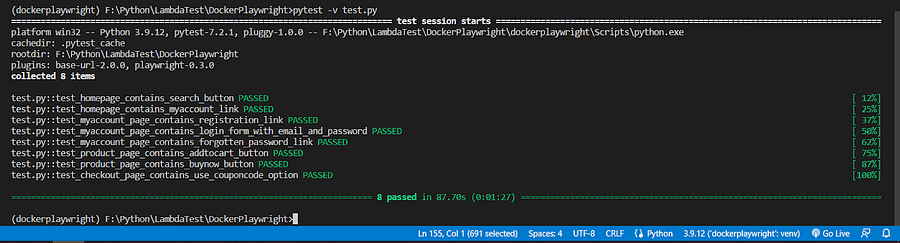
Now that we’ve written 8 comprehensive test cases, let’s run them first without dockerizing them to ensure they are working correctly. All the tests are saved in a file test.py, and to run them, we run the pytest -v test.py command. The -v flag is for verbose output. As we can see from the screenshot below, all test cases are running perfectly.
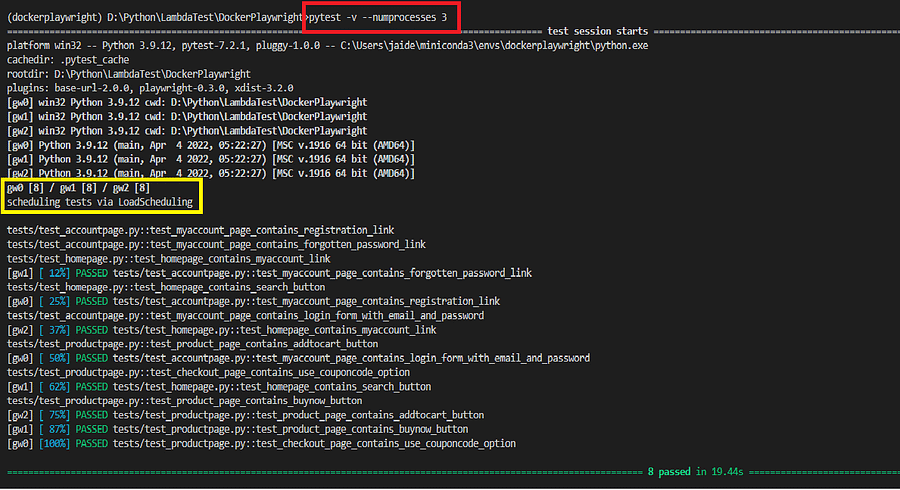
As the number of tests increases, we can leverage the multi-core CPU to run tests in parallel using the –numprocesses <number_of_processes> option of pytest. The performance and number of parallel processes we can spawn depend on the configuration of the host CPU.
For demo purposes, since we have 8 tests, we will set it to 3 to run 3 tests at a time. As you can see from the image below 3 different workers were spawned, and tests were run parallel depending on the availability of the workers. Parallel execution is an excellent way to speed up test execution for larger test suites.
Freezing The Python Requirements
Now that the tests are perfectly running locally, before proceeding to dockerizing the tests, we will export all the Python dependencies we installed in the virtual environment in the requirements.txt file. This is a standard process in the Python world to share dependencies. Further reading about freezing requirements is available in the official pip documentation.

Below are the contents of the generated requirements.txt file, which contains the dependency name and the version. Now, we can share this with other team members and colleagues to ensure everyone uses the same Python libraries.
attrs==22.2.0
certifi==2022.12.7
charset-normalizer==3.0.1
colorama==0.4.6
exceptiongroup==1.1.0
greenlet==2.0.1
idna==3.4
iniconfig==2.0.0
packaging==23.0
playwright==1.30.0
pluggy==1.0.0
pyee==9.0.4
pytest==7.2.1
pytest-base-url==2.0.0
pytest-playwright==0.3.0
python-dotenv==0.21.1
python-slugify==8.0.0
requests==2.28.2
text-unidecode==1.3
tomli==2.0.1
typing_extensions==4.4.0
urllib3==1.26.14
Running Playwright Docker Tests Locally
Running Playwright Docker tests locally allow you to test your Playwright scripts in a containerized environment, which can help ensure consistency and reproducibility across different environments.
In this Playwright Docker tutorial, we will go through the steps to set up and run Playwright with Docker on your local machine. We will cover how to create a Dockerfile, build a Docker image, and run a container with Playwright and Python installed. By the end of this Playwright Docker tutorial, you will have a working setup to run Playwright in a Docker container on your local machine.
Simplify your CSS to SASS conversion with our free tool! Start now!
Writing The Docker File
Now that the Playwright Docker tests are working locally, let’s move on to converting them to a Docker image. For that, we will first need a Docker file. By convention, the name of the file is Dockerfile. We will create this in the project’s root directory, i.e., outside the tests folder.
FROM mcr.microsoft.com/playwright/python:v1.30.0-focal
WORKDIR /app
COPY pages /app/pages
COPY tests /app/tests
COPY utilities /app/utilities
COPY requirements.txt /app/
RUN pip install --no-cache-dir --upgrade pip && pip install --no-cache-dir -r requirements.txt
Walkthrough Of DockerFile
The first line tells Docker to pull the Python Playwright Docker image from Docker Hub.
We create a working directory called /app.
We copy the pages directory, which contains all the object representations of the web pages into /app/pages.
This is followed by copying the tests and the utilities directories to /app/tests and /app/utilities, respectively.
Next, we copy the requirements.txt into the Docker container.
We upgrade pip and install the dependencies from the requirements.txt file we copied in the above step.
Building The Docker Image
The next step is building the Docker image. We talked about what an image is earlier in this Playwright Docker tutorial. The command to build the image is below.
docker build -t playwright-docker
The output of the process is shown below.
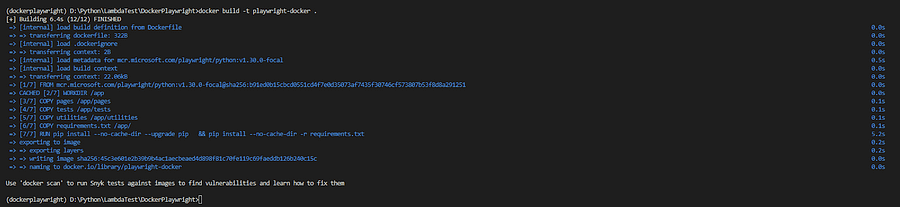
docker build is the command to build images.
-t is shorthand for name and optionally a tag to the resulting image being built. We have chosen playwright-docker, and since the tag, which can also be called version, is omitted will be defaulted to the latest.
The period ‘.’ tells Docker that the Dockerfile is in the current directory.
The created image can be viewed by using the docker image ls command.

Running The Tests In Docker Container
Running the containers can simply be done using the docker run command.
docker run -it playwright-docker pytest -v
This will run the Playwright Docker tests, and here is the output.

Similar to local execution, we can also run the Playwright Docker tests in parallel in a Docker container.
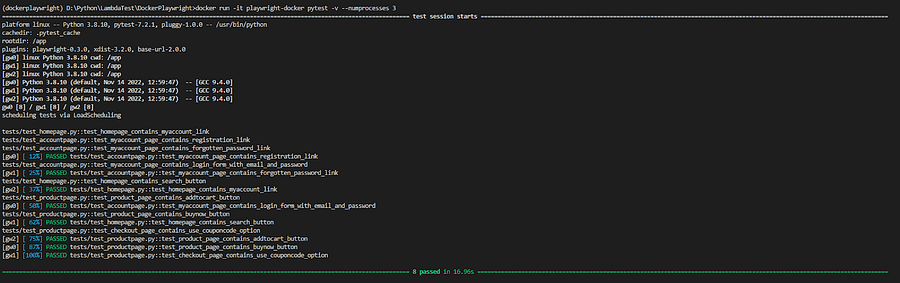
We defaulted the fixture to always run on the local grid, remember?
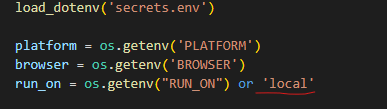
But the code is designed to operate based on the environment variables configured in the secrets.env file. In Docker, to explicitly pass env variables, the best practice is to add all the environment variables in a key value file. This file can be passed to the docker run command when we run the container.
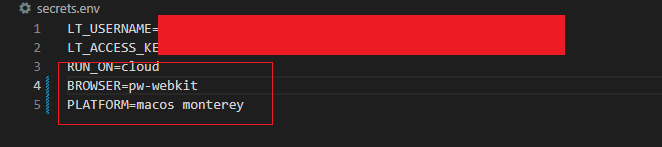
Just to remind you, here is what the secrets.env file looks like for us.
To run the docker container by passing it the env file, we need to leverage the — — env-file flag and the docker run command.
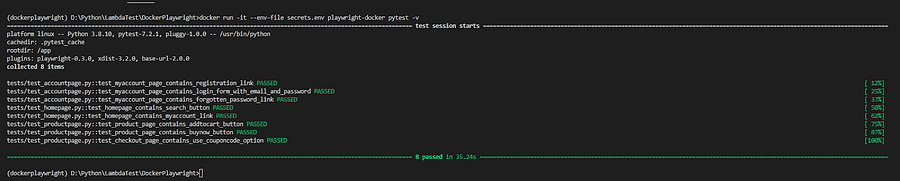
docker run -it — env-file secrets.env playwright-docker pytest -v
The below snapshot shows the result of the container run.
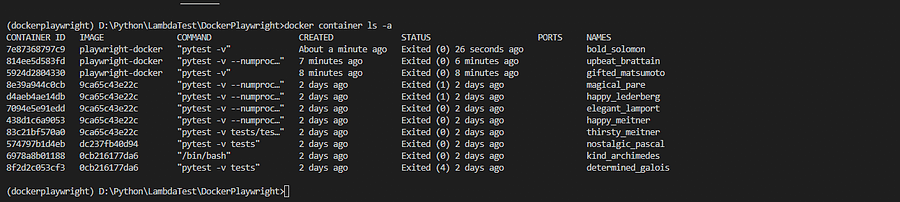
docker container ls -a command can be used to view a history of all the containers that have been run so far
Running Playwright Docker Tests On The Cloud Grid
So far, it’s clear to notice that running the Playwright Docker tests locally has some disadvantages in terms of choices of browsers and operating systems. The problems of browsers are easy to get around by installing various browsers, and the Playwright Docker image also comes pre-baked with all the browsers.
However, the issue of conducting Playwright Docker tests on different operating systems persists. How can this be resolved? One possible solution is to utilize a cloud grid provider such as LambdaTest.
Cloud testing platforms like LambdaTest offer the capability to conduct Playwright automated testing on a large scale, significantly reducing the time it takes to run these Playwright tests. With access to a browser farm of over 50 different versions of popular browsers such as Chrome, Chromium, Microsoft Edge, Mozilla Firefox, and Webkit, you can efficiently execute your Playwright Docker tests.
You can also subscribe to the LambdaTest YouTube Channel and stay updated with the latest tutorial around Selenium testing, Cypress E2E testing, Appium, and more.
To leverage LambdaTest Docker grid, we need a username and access key, which is available in the LambdaTest Profile Section once we create an account. We will now modify the secrets.env file to add the username and access key as two more environment variables named LT_USERNAME and LT_ACCESS_KEY.
The RUN_ON variable has also been modified to toggle the pytest fixture to initialize the connection to the cloud grid.

We do not need to rebuild the Docker image since we control the behavior externally via environment variables. Another good reason we should use environment variables to store controlling flags and data which drive the code behavior.
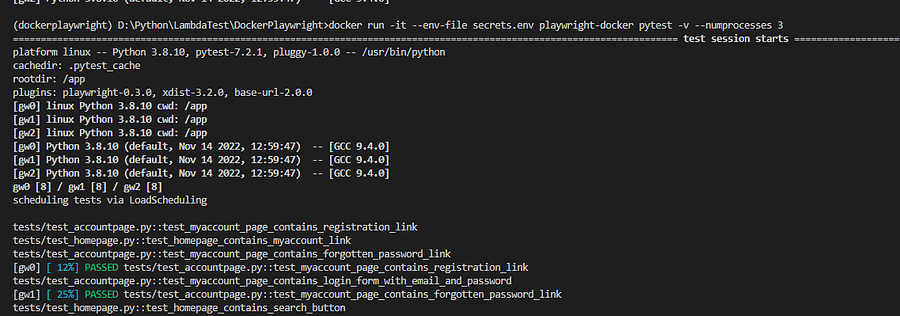
Let’s now rerun the Docker container with three parallel Playwright Docker tests.
docker run -it –env-file secrets.enf playwright-docker pytest -v –numprocesses 3
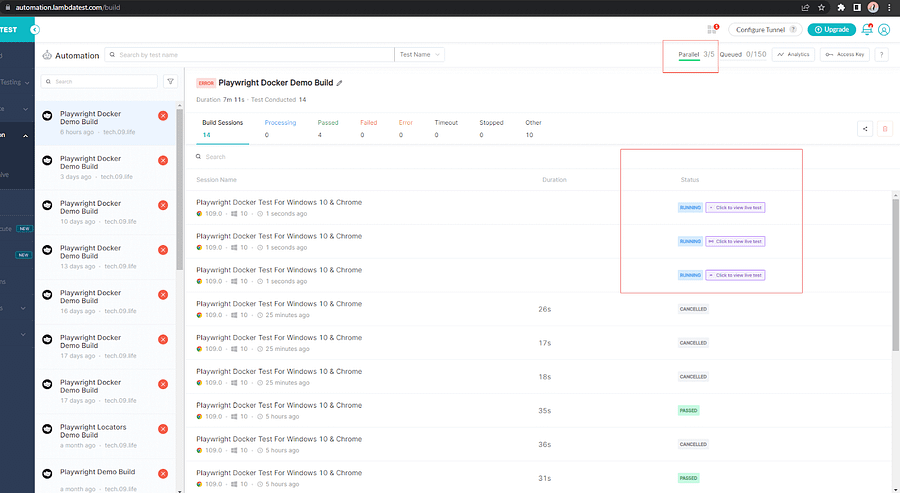
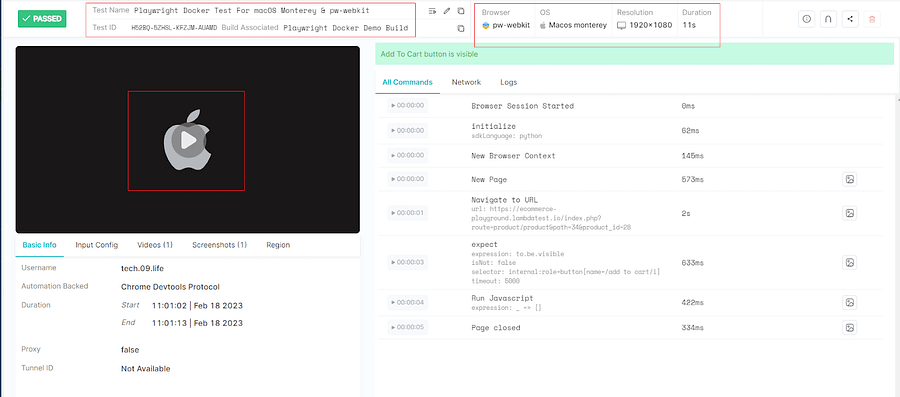
Below snapshot from the LambdaTest Dashboard shows the three Playwright Docker tests executing in parallel. The browser and OS we chose are also shown as small icons, along with the test results.
If we open one of the individual Playwright Docker tests, we can also get a finer view of the test run along with the steps, screenshots, video of execution, browser and OS, and other details.
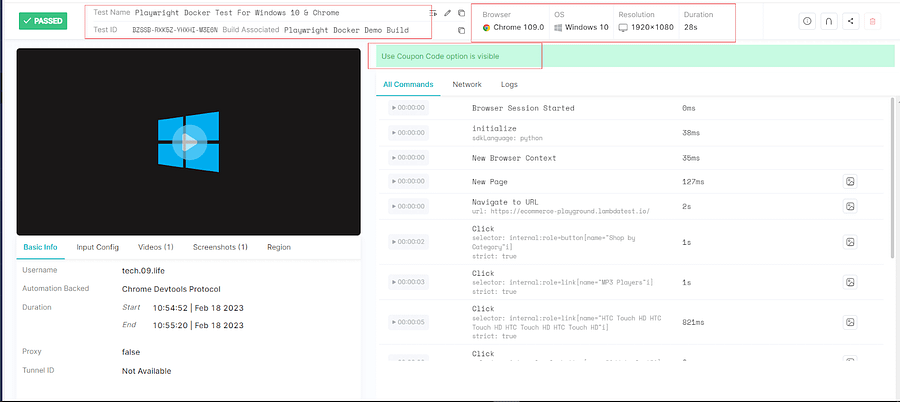
Now, let’s run the same Playwright Docker tests on macOS and Safari. For that, we will need to modify the environment file secrets.env to amend the BROWSER and PLATFORM variables. Here is how the updated file now looks after the changes.
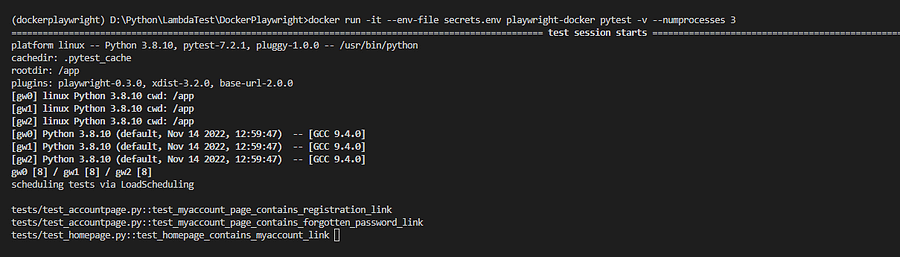
There is no need to rebuild the image; we can simply run it using the docker run command below.
docker run -it — env-file secrets.env playwright-docker pytest -v –numprocesses 3
Here is the new snapshot of the LambaTest Dashboard, again notice the browser and OS version are clearly shown as icons verifying that the Playwright Docker tests did indeed run on the configurations we made in the secrets.env file.
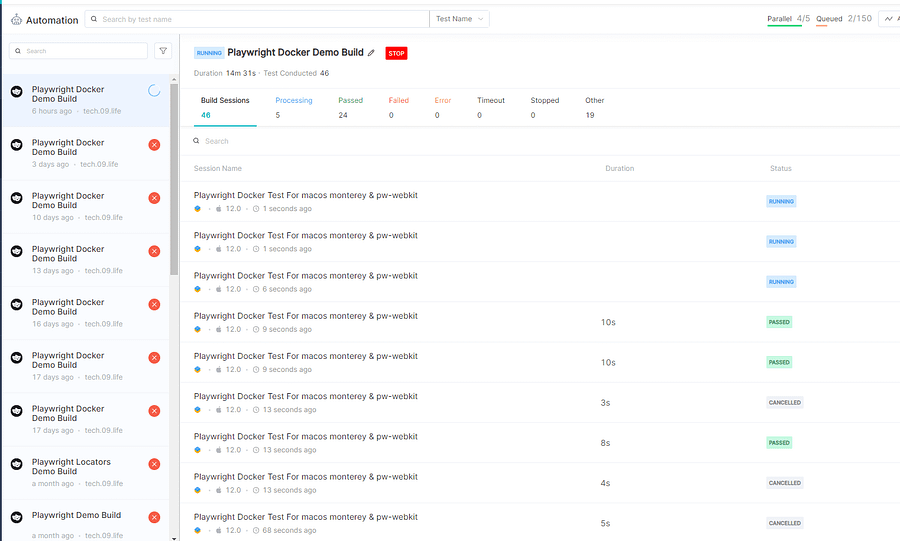
And to see the details of an individual test, we can open it and check for the execution details.
Docker Compose For Running Multi-Container Docker Applications
For this Playwright Docker tutorial, we have written eight tests and built a single Docker image for them. It’s easy to run the docker run command for one image. But for testing more complicated solutions with many containers and dependencies on other containers, the docker run is less than ideal. To run such multi-container applications, Docker provides an efficient tool called docker compose.
The docker compose the need to use the docker run command and can start all the containers in a single command. All we need to do is define the setup in a yaml file. The use of Docker compose in Production is always debated and unsuitable for all. This Stack Overflow discussion is nice for getting a better idea.
But for local testing, we can use it. Let’s see that in the next section of this Playwright Docker tutorial.
Writing The Docker Compose File
To leverage docker compose, we need to write a special file called docker-compose.yaml.
version: '3.9'
services:
testing:
image: playwright-docker
env_file:
- ./secrets.env
The first line version of the file contains the docker compose version. Details of which version to use can be obtained from the official Docker docs.
The next line of services is the start of the service definition, i.e., all containers this docker-compose will start.
The next line of testing is the name of the service. It can be any meaningful name that defines what the service does.
The following line image defines which image to use. If present locally, it will be used; otherwise, Docker compose will try to pull it from the Docker hub.
Instead of image, we can also use the build and give it the location of the Dockerfile, and the image will be built locally.
The next file, env_file, is where we pass the env file we define.
Execution
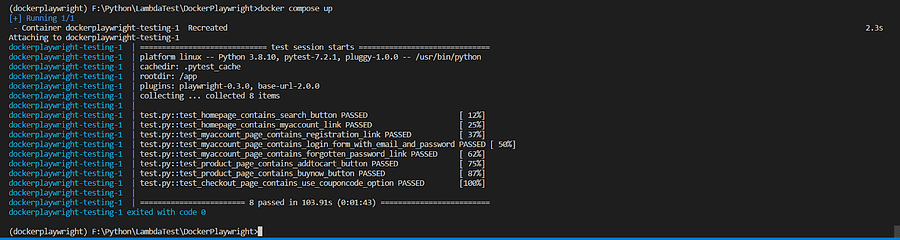
Let’s now run the container using the docker compose up command, and we can see all the Playwright Docker tests are still running, but the command needed to do it has been greatly simplified.
Conclusion
In conclusion, using Docker to run Playwright tests has many benefits. By building and running tests inside Docker containers, we can ensure that the Playwright Docker tests run in a consistent environment, regardless of the host machine on which they run. This can help to eliminate environment-specific bugs and make it easier to reproduce issues.
One advantage of using Docker to run Playwright tests is the ability to easily supply environment files with sensitive data, such as access keys and usernames. We could also use the env file to toggle between running Docker locally and on the cloud Docker grid. Creating separate environment files for each environment (e.g., development, staging, production) allows us to easily switch between environments without modifying the test code.
Additionally, using Docker Compose to orchestrate the test environment can simplify the process of spinning up and tearing down the necessary services for the Playwright Docker tests. By defining the services in a YAML file and running a single command, we can start all the services needed for the tests, including databases and web servers, and ensure that they are properly configured and running before running the tests.
Overall, running Playwright Docker tests can make the testing process more efficient, reliable, and secure. Whether we are running tests locally or in a continuous integration environment, Docker can help to streamline the process and ensure that the Playwright Docker tests are running in a consistent environment, with the necessary services and data available.