


Table of contents
- Quick Recap about Playwright
- What are Playwright Locators?
- How to install and set up Playwright?
- Sync vs Async Playwright
- Recommended Playwright Locators
- Prerequisites
- Locating Elements by Role in Playwright
- Locating Elements by Text in Playwright
- Locating Multiple Elements by Regular Expressions in Playwright
- Locating Form Elements by Label in Playwright
- Locating Input Elements by Placeholder in Playwright
- Locating Image Elements by Alt Text in Playwright
- Locating Elements by Title in Playwright
- Locating Elements by Test ID in Playwright
- Playwright Locators using CSS and XPath
- Filtering and Chaining Playwright Locators
- Filtering vs Chaining
- Filtering Playwright Locators
- Chaining Playwright Locators
- Playwright Locator Methods
- Constructing Locators using Playwright’s Test Generator
- Test Generator in Action
- Conclusion
End-to-end testing is essential for ensuring the quality and usability of a website or web application. And a crucial aspect of end-to-end testing is the ability to reliably, correctly, and easily locate elements on a web page. The process of locating elements involves identifying and interacting with elements on a web page, such as buttons, links, and text fields, to evaluate their behavior and functionality.
Web development frameworks and technologies are constantly evolving. Single Page Applications(SPA) are perfect examples where a single document is loaded, which receives dynamic updates, behaves differently across different browsers, uses asynchronous requests, and has complex state management.
The increasingly dynamic nature of web applications makes it paramount to have a robust, reliable, and accurate method for locating and interacting with elements on a web page. Resilient and non-flaky tests can help test every aspect of the website (or app). How can I not mention Playwright when referring to non-flakiness in tests 🙂
Playwright is an open-source automation testing framework, which enables reliable end-to-end testing of web applications. It supports multiple languages, including Python, JavaScript, Java, and .Net, making it flexible for different developer communities. It also works seamlessly across different browsers and operating systems.
One of the powerful ways to locate elements for web testing is by using Playwright locators. Playwright locators are the central piece of Playwright’s auto-waiting and retry-ability, making it easy for developers and testers to interact with specific elements on a web page, and it enables the creation of test scripts that can interact with those elements.
To understand the preferences and trends within the testing community, we conducted a LinkedIn poll asking, ‘What is your favorite element locator in test automation? The responses provided a clear preference, that is Xpath among professionals. This interesting revelation highlights the significant role of XPath in test automation.
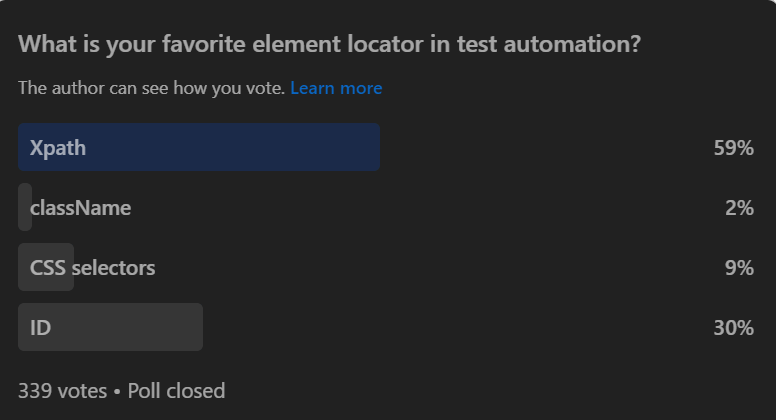
In this blog on Playwright locators, we will dive deep into various locator strategies that can be used with Playwright for finding web elements while performing automation testing. If you are preparing for an interview you can learn more through Playwright interview questions.
So, let’s get started!
Quick Recap about Playwright
Playwright is the latest entrant into the array of frameworks (e.g., Selenium, Cypress, etc.) available for web automation. It enables fast and reliable end-to-end testing for modern web apps.
At the time of writing this Playwright locators blog, the latest stable version of Playwright is 1.30.0, and Playwright is now consistently hitting the >20K download per day mark, as seen from PyPi Stats.
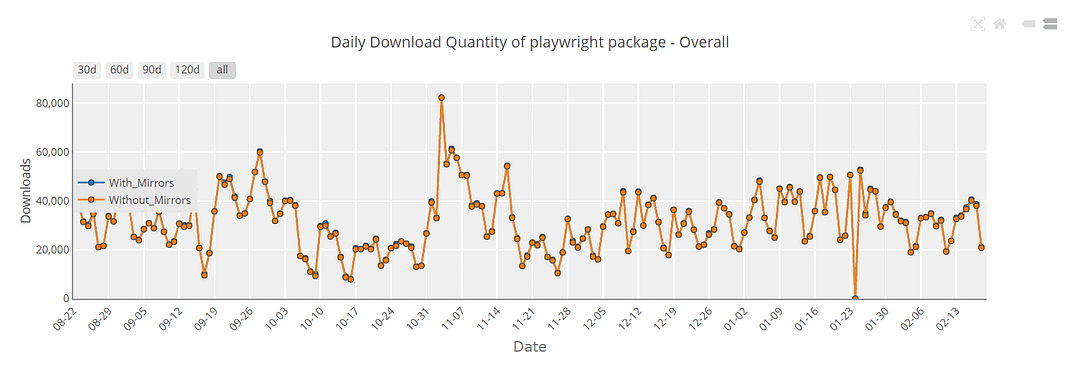
Below are the download trends of Playwright in comparison to a popular alternative, Selenium, taken from Pip Trends.
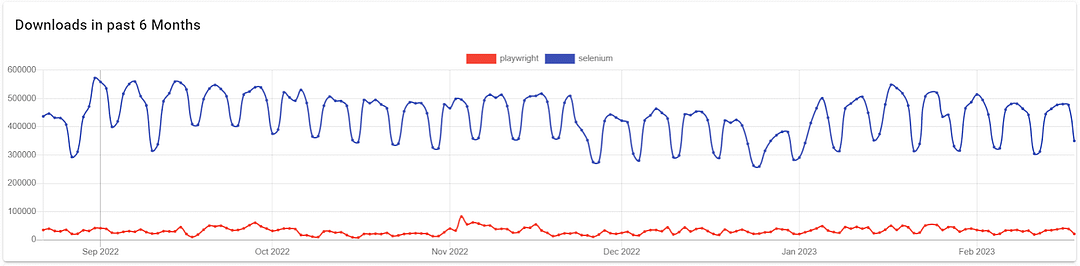
A key consideration when using any language, tool, or framework is its ease.
Revolutionize your UI testing with AI-powered Smart Visual UI Testing. Ensure visual perfection across 3000+ environments. Start Testing Now.
Key features of Playwright:
Support for all modern browsers including Chromium, Firefox, Microsoft Edge, and WebKit
Playwright APIs are available in different languages such as Python, Java, JavaScript, TypeScript, and .NET.
Playwright is cross-platform. Hence tests work seamlessly on Windows, macOS, and Linux in both headless & non-headless modes.
Playwright supports auto-wait, eliminating the need for artificial timeout, making the tests more resilient & less flaky.
Playwright locators provide unique & simple ways to find elements on websites built using modern frameworks.
Playwright offers a unique codegen tool that assists in locating elements
Playwright locators combined with its rich & easy-to-use APIs make it the perfect choice for end-to-end testing of web applications allowing simpler-than-ever access to elements on websites built using modern web frameworks. You can go through this blog on Playwright end-to-end testing to learn more about it.
In the further sections of this blog on Playwright locators, I will dive deep into the different locators that can be used for locating elements on the AUT.
To find more use cases of using Playwright, you can refer to this blog on Playwright for web scraping.

What are Playwright Locators?
The Playwright locators are at the heart of the Playwright’s ability to automate actions and locate elements on the web page. In layman’s terms, Playwright locators are a way for our scripts to interact with a specific element on a webpage.
Playwright locators are equipped with auto-wait and retry abilities. This means that the locator will wait for the elements to load & keep retrying automatically before throwing TimeoutError. You can learn more about it through this blog on handling exceptions in automation testing.
There are several ways of getting started with Playwright locators, first using the page.locator() method to create our locators, which can work with CSS or XPath, and secondly, using the built-in locators.
While Playwright is fully flexible in allowing us to build our custom locators using page.locator() the built-in locators are recommended and serve most use cases.
Key Features of Playwright Locators:
Built-in locators capable of locating elements using ARIA Roles, text, alt-text, placeholders, titles, labels, and custom test-ids.
Ability to chain & filtering locators provides precision to narrow the search for the element.
Fully flexible in working with CSS & XPath if required.
Locators work on the most up-to-date DOM everytime action is performed using them, ensuring reliable tests.
Built-in support for auto-wait and retry, helping write resilient and non-flaky tests.
Built-in methods available to perform various actions on located elements.
Run Automated Playwright Tests Online. Try LambdaTest Now!
How to install and set up Playwright?
Before we explore Playwright locators, let’s set up our development environment quickly. Also, if you already have Playwright installed on your machine, please hop on to the Sync vs Async Playwright section to know why I have used sync APIs for testing.
Playwright is flexible and allows working with various languages such as Python, NodeJs, Java, .NET, JavaScript, and TypeScript. For this blog on Playwright locators, we will use the Python API of Playwright.
Creating a dedicated virtual environment:
Create a dedicated folder for our project called playwright locators (This step is not mandatory but good practice).
Inside the folder we just created, use the built-in venv module to create a virtual environment named playwright locators.
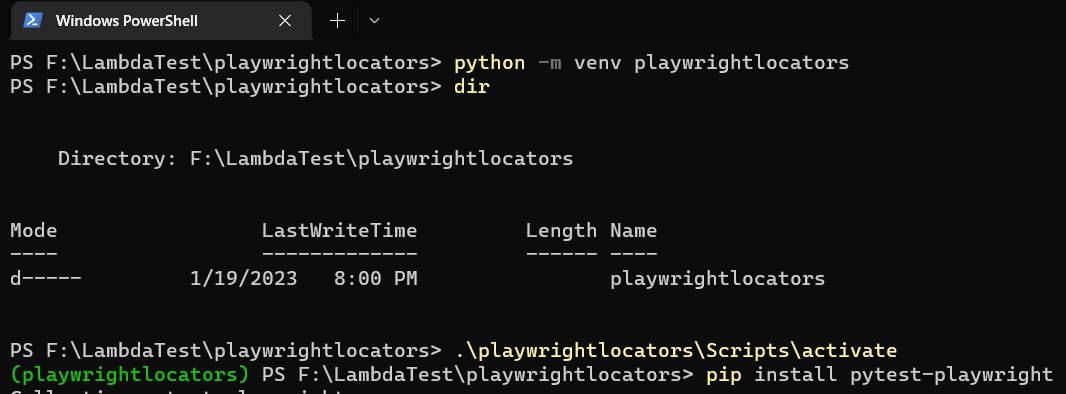
3. Activate the virtual environment by calling the activate script.
4. Install the Playwright module using pip install pytest-playwright.
5. Lastly, install the required browsers using playwright install

All the tests written in this blog have been thoroughly tested on the following versions
Python 3.9.12, pytest 7.2.1, and Playwright 1.29.1.

Automate visual testing effortlessly with our Smart Visual UI Testing. Achieve flawless UIs on every device and browser. Try it Today.
Sync vs Async Playwright
As mentioned above, we will use the Python API of Playwright for this Playwright locators tutorial and more specifically, the sync_api version. The reason for choosing sync_api as mentioned in the answer on Stack Overflow is that the sync_api is simply a wrapper around Python’s asyncio_api. So Playwright makes async calls under the hood.
When using other languages based on the support, it’s best to choose the appropriate, i.e., sync or async API. Let’s use the Playwright Test Generator tool to confirm this understanding.
When running, the test for Python generates code that uses sync_api, as seen from the screenshots below.
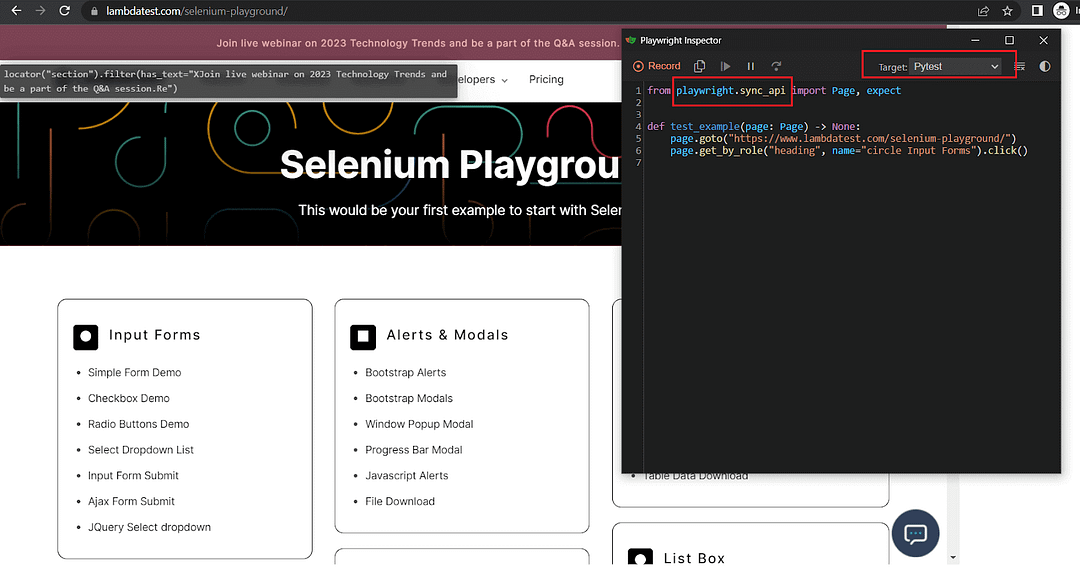
When running, the test for Javascript generates code that uses async_api, as seen from the screenshots below.
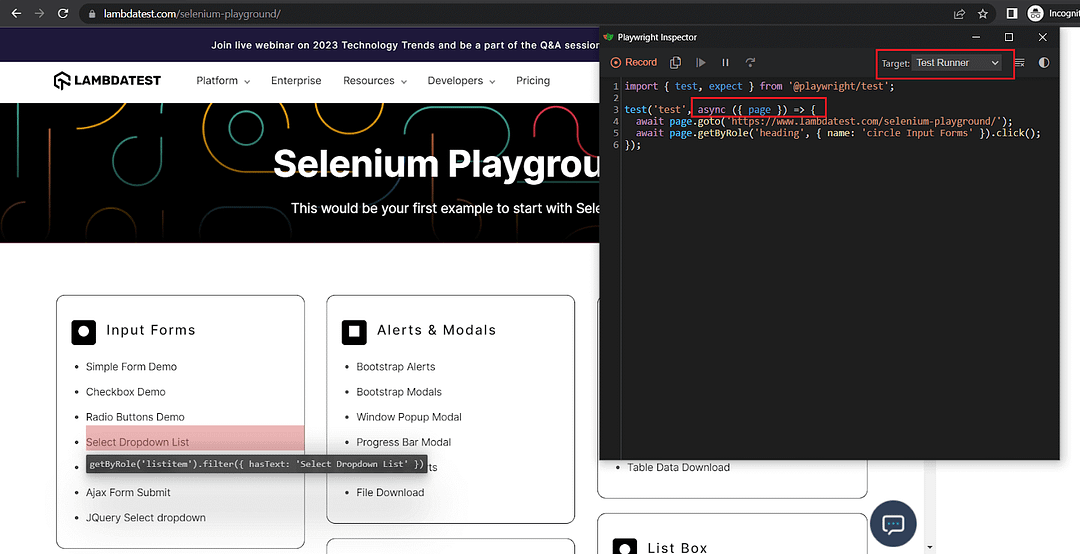
So, when using Playwright with Python, feel free to use sync_api unless you need fine control over the request behavior in which you can use async_api.
Recommended Playwright Locators
Playwright provides flexibility to use the page.locator() method to locate elements using CSS & XPath, but it’s not recommended. We will discuss why it’s not recommended in the later section of this Playwright locator tutorial.
Instead, Playwright provides seven built-in locators recommended and sufficient for locating any elements on any web page or website. Let’s now explore in detail the recommended built-in Playwright locators one by one.
All the tests demonstrated hereafter have been run on the LambdaTest cloud grid. However, the tests are fully compatible with running on local machines. When running locally, just use the correct pytest fixture mentioned in the section below.
Cloud testing platforms like LambdaTest allow you to perform Playwright automated testing at scale, dramatically reducing the time taken to run your Playwright tests. You can run your tests on an online browser farm of 50+ browsers and browser versions of Chrome, Chromium, Microsoft Edge, Mozilla Firefox, and even Webkit.
You can also subscribe to the LambdaTest YouTube Channel and stay updated with the latest tutorial around Selenium testing, Cypress E2E testing, Appium, and more.
Prerequisites
To use LambdaTest with Playwright, you must set up the necessary imports and dependencies along with the username and access key to run the test on the LambdaTest cloud grid.
Setting up the imports and LambdaTest cloud grid username & access key
The load_dotenv(“sample.env”) reads the username & access key required to access the Playwright on the LambdaTest cloud grid. The username and access key are available on the LambdaTest Profile Page.
import json
import os
import re
import subprocess
import sys
import urllib
import pytest
from dotenv import load_dotenv
load_dotenv("sample.env")
Setting up the Capabilities
The capabilities dictionary contains the configuration of our test environment on the LambdaTest Playwright grid. The configurations encompass various parameters, such as the preferred browser, its specific version, the operating system required to execute the tests, and other relevant settings.
capabilities = {
'browserName': 'Chrome', # Browsers allowed: `Chrome`, `MicrosoftEdge`, `pw-chromium`, `pw-firefox` and `pw-webkit`
'browserVersion': 'latest',
'LT:Options': {
'platform': 'Windows 10',
'build': 'Playwright Locators Demo Build',
'name': 'Playwright Locators Test For Windows 10 & Chrome',
'user': os.getenv('LT_USERNAME'),
'accessKey': os.getenv('LT_ACCESS_KEY'),
'network': True,
'video': True,
'visual': True,
'console': True,
'tunnel': False, # Add tunnel configuration if testing locally hosted webpage
'tunnelName': '', # Optional
'geoLocation': '', # country code can be fetched from https://www.lambdatest.com/capabilities-generator/
}
}
Setting up the pytest fixtures:
We set up two fixtures, one for our cloud grid and the other for our local grid. So it becomes easy to switch between local & cloud depending on where you want to run the tests.
Use the local_grid_page fixture when you run the tests on the local machine.
@pytest.fixture(name="local_grid_page")
def playwright_local_grid_page():
with sync_playwright() as playwright:
browser = playwright.chromium.launch(headless=True)
page = browser.new_
Use the cloud_grid_page fixture when you wish to run the tests on the LambdaTest cloud grid.
@pytest.fixture(name="cloud_grid_page")
def playwright_local_grid_page():
with sync_playwright() as playwright:
playwrightVersion = str(subprocess.getoutput('playwright --version')).strip().split(" ")[1]
capabilities['LT:Options']['playwrightClientVersion'] = playwrightVersion
lt_cdp_url = 'wss://cdp.lambdatest.com/playwright?capabilities=' + urllib.parse.quote(json.dumps(capabilities))
browser = playwright.chromium.connect(lt_cdp_url)
page = browser.new_page()
yield page
In this pytest Tutorial, learn how to use pytest fixtures with Selenium and how to set up your test using the pytest.fixture() decorator.
Locating Elements by Role in Playwright
The locator get_by_role() allows locating elements by their ARIA role, ARIA attributes, and accessible name. ARIA stands for Accessible Rich Internet Applications. It’s a set of attributes that can be added to HTML elements to help people who use assistive technologies, like screen readers, navigate and understand web content more easily.
ARIA roles are like labels for different parts of a website, like headings, buttons, and links. These labels help people who use assistive technologies understand the different parts of the website and how to use them.
Let’s understand the get_by_role() Playwright locator using the LambdaTest eCommerce website and one of the ARIA roles, a button.
Test Scenario:
Demo website home page should contain the ‘Search’ button.
‘Search’ button should have a CSS class ‘type-text’.
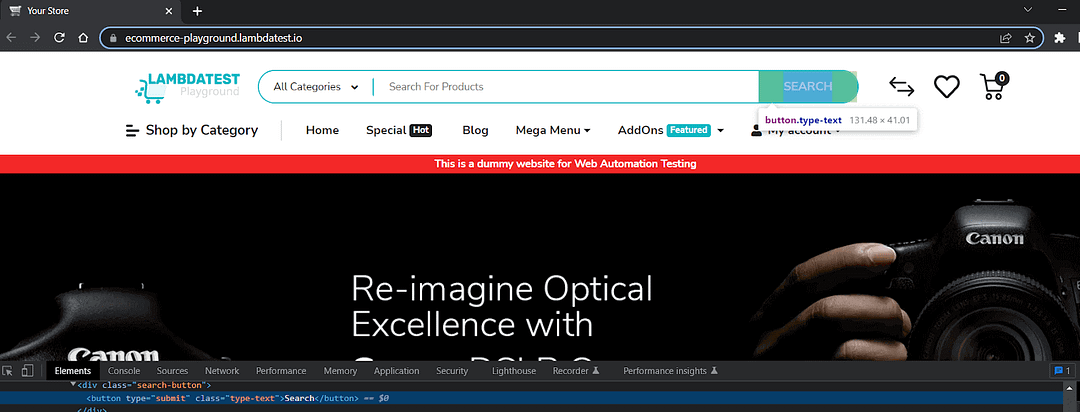
Sample Implementation:
# replace cloud_grid_page with local_grid_page while running on local
def test_homepage_contains_search_button(cloud_grid_page):
cloud_grid_page.goto("https://ecommerce-playground.lambdatest.io/")
search_button_locator = cloud_grid_page.get_by_role(role="button", name="Search")
expect(search_button_locator).to_have_class("type-text")
Execution:
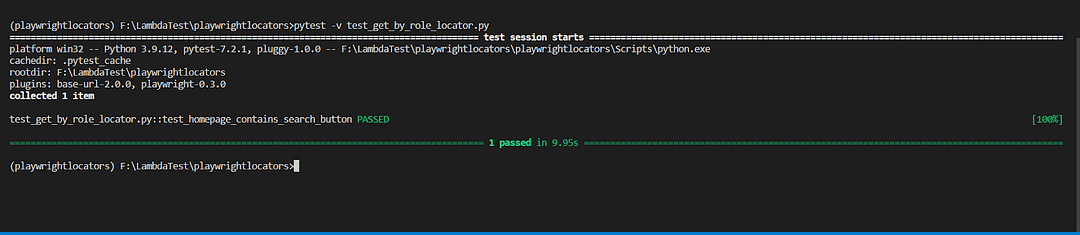
Code Walkthrough:
Upon inspection of the homepage we see that ‘Search’ is a button of the type submit and has a CSS class=’type-text’ assigned to it.
Use the Playwright locator get_by_role() with arguments as role=‘button’ and name=’Search’.
The expect() Playwright assertion then checks if the located element has class=type-text using the to_have_class() method.
It’s worth mentioning that for the get_by_role() Playwright locator, only the role argument is mandatory. All other arguments are optional, including the name we used. An important optional argument is exact. It can be used to force an exact case-sensitive and whole-string match.
Let’s now move to the next Playwright locator, where we will demo the exact match argument.
Streamline your app development with Visual Studio App Center on LambdaTest. Automate your app testing on real devices effortlessly. Learn How.
Locating Elements by Text in Playwright
The locator get_by_text() allows finding elements by the text it contains. This fully versatile Playwright locator can match exact string and substring and also allows using regular expressions.
This Playwright locator is recommended for finding non-interactive elements such as those contained within HTML tags div, span, and p. Let’s see this Playwright locator in action using a few scenarios to explore exact matches and regular expressions.
For this, we again use the LambdaTest eCommerce website.
Test Scenario:
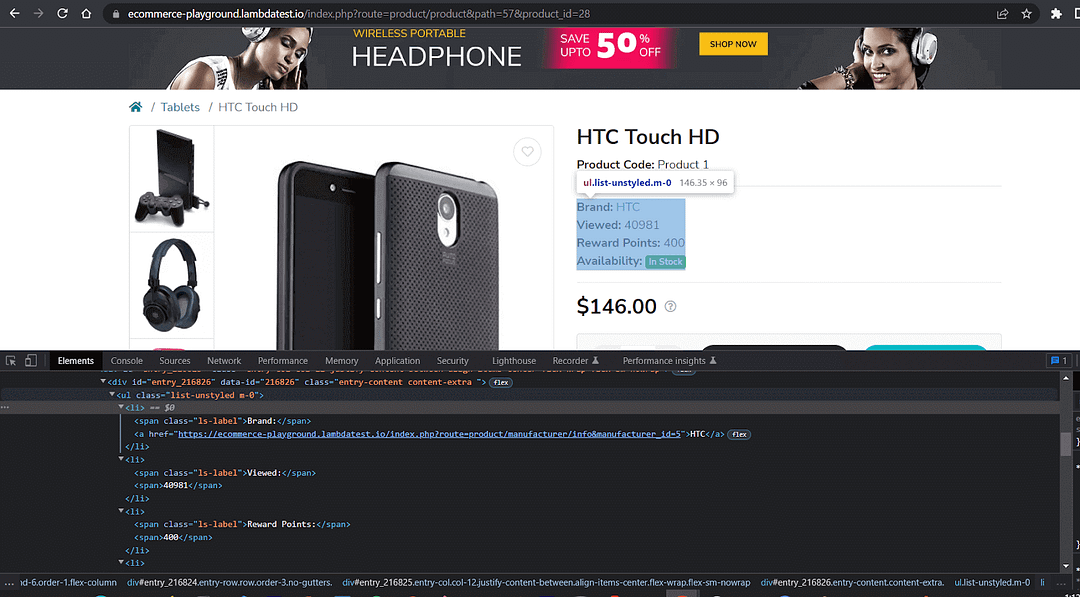
Product page should contain the exact texts for product details:
Brand:
Viewed:
Reward Points:
Availability:
Sample Implementation:
# replace cloud_grid_page with local_grid_page while running on local
def test_product_details_text_should_be_visible(cloud_grid_page):
cloud_grid_page.goto(
"https://ecommerce-playground.lambdatest.io/index.php?route=product/product&path=57&product_id=28"
)
brand_text_locator = cloud_grid_page.get_by_text(text="Brand:", exact=True)
viewed_text_locator = cloud_grid_page.get_by_text(text="Viewed:", exact=True)
points_text_locator = cloud_grid_page.get_by_text(text="Reward Points:", exact=True)
availability_text_locator = cloud_grid_page.get_by_text(text="Availability", exact=True)
expect(brand_text_locator).to_be_visible()
expect(viewed_text_locator).to_be_visible()
expect(points_text_locator).to_be_visible()
expect(availability_text_locator).not_to_be_visible()
Execution:

Code Walkthrough:
Upon inspecting the product page, we see the details within the < span > tag.
The steps to navigate the product page remain the same as in the previous test case.
In the next steps, we use the get_by_text() Playwright locator to match the texts for ‘Brand:’, ‘Viewed:’, and ‘Reward Points:’. We use the expect() assertion on each of the three locators and call the to_be_visible() method.
For the ‘Availability’, we exclude the ‘:’ to demonstrate that the exact argument works. Since we know the exact match, in this case, will fail on the expect() assertion, we call the not_to_be_visible() method.
Playwright provides positive and negative assertion methods; we’ve used both in this example.
Locating Multiple Elements by Regular Expressions in Playwright
Whilst we saw exact matches while testing modern web applications, we frequently may need to look for approximate matches, and Playwright locators have us covered.
We can use regular expressions to locate multiple elements. Let’s quickly look at an example.
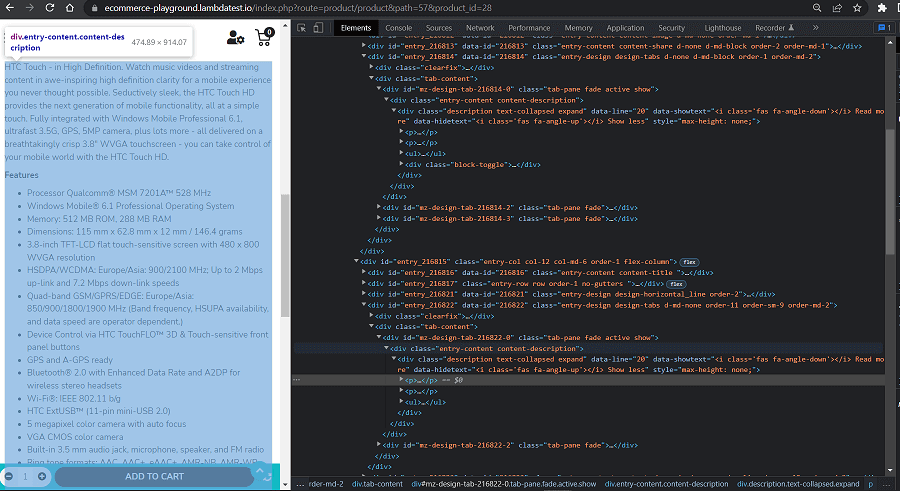
Test Scenario:
Product page multiple occurrences of the brand ‘HTC’.
There should be 10 matches.
Sample Implementation:
# replace cloud_grid_page with local_grid_page while running on local
def test_product_name_to_appear_more_than_once(cloud_grid_page):
cloud_grid_page.goto(
"https://ecommerce-playground.lambdatest.io/index.php?route=product/product&path=57&product_id=28"
)
brand_name_locator = cloud_grid_page.get_by_text(re.compile("htc", re.IGNORECASE))
expect(brand_name_locator).to_have_count(10)
Execution:

Code Walkthrough:
Upon inspecting the product page, we know that there are 10 occurrences of the brand name ‘htc’.
The part of opening the product page remains the same.
In preparing the locator, we use the Python ‘re’ module to match all occurrences and also use IGNORECASE.
On the expect() assertion, we call the to_have_count() method to complete our test.
Locating Form Elements by Label in Playwright
Almost all websites have form fields, and most form controls usually have dedicated labels that could be conveniently used to interact with the form. Playwright locators provide a convenient way of locating form elements using the get_by_label() locator.
Let’s jump into a demo using the LambdaTest eCommerce website.
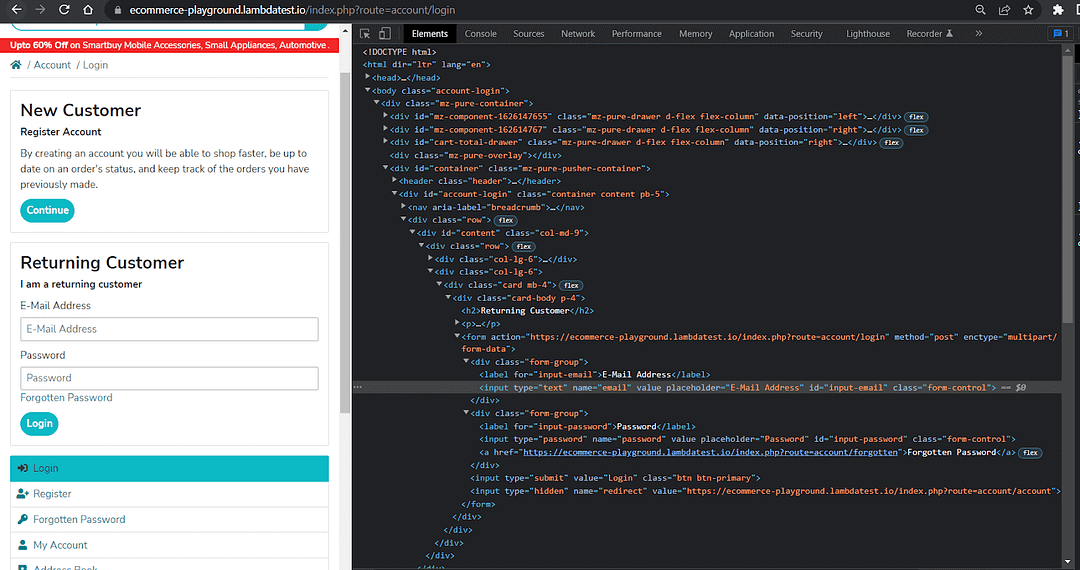
Test Scenario:
The login form should have exactly one Email Address label.
The login form should have exactly one Password label.
Sample Implementation:
# replace cloud_grid_page with local_grid_page while running on local
def test_exactly_one_email_and_password_field(cloud_grid_page):
cloud_grid_page.goto(
"https://ecommerce-playground.lambdatest.io/index.php?route=account/login"
)
email_address_locator = cloud_grid_page.get_by_label(text="E-Mail Address", exact=True)
password_locator = cloud_grid_page.get_by_label(text="Password", exact=True)
expect(email_address_locator).to_have_count(1)
expect(password_locator).to_have_count(1)
Execution:

Code Walkthrough:
The part till we goto() the login page remains the same.
Initialize two locators using get_by_label(), one of Email & Password with the exact=True to confirm that only one login form element exists.
On the expect() assertion, we call the method to_have_count(1) to test only one of each email & password field.
Locating Input Elements by Placeholder in Playwright
Most websites have several forms for login, registration, reviews, and customer support. And forms usually have a placeholder text to assist the user in correctly filling forms.
Playwright locator get_by_placeholder() comes in handy when locating elements using the placeholder text. Our LambdaTest eCommerce demo website has a review form that can be used to explore this locator.
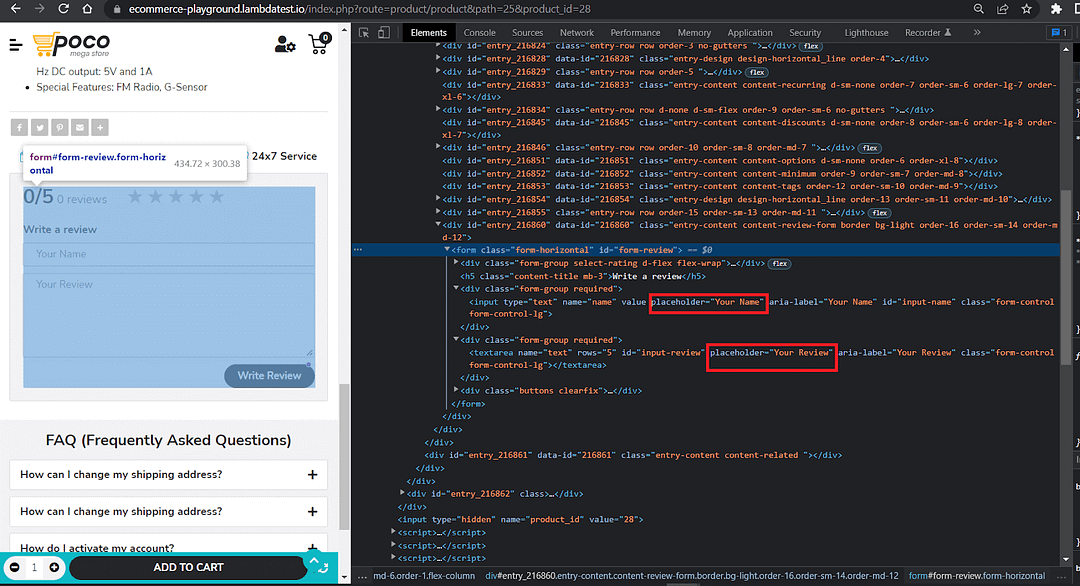
Test Scenario:
The review form should have one field for the customer name.
The review form should have one field for customer review.
Sample Implementation:
# replace cloud_grid_page with local_grid_page while running on local
def test_review_form_has_customername_customerreview_fields(cloud_grid_page):
cloud_grid_page.goto(
"https://ecommerce-playground.lambdatest.io/index.php?route=product/product&path=25&product_id=28"
)
name_locator = cloud_grid_page.get_by_placeholder(text="Your Name", exact=True)
review_locator = cloud_grid_page.get_by_placeholder(text="Your Review", exact=True)
expect(name_locator).to_have_count(1)
expect(review_locator).to_have_count(1)
Execution:

Code Walkthrough:
Upon inspecting the demo website, we can spot the placeholder texts for the review section.
We use the name of these placeholders as an argument to the get_by_placeholder() locator. We also only look for an exact matching by setting the argument exact=True.
Calling to_have_count(1) on the except() assertion then helps to test our scenario of only one reviewer name field and review input field.
Locating Image Elements by Alt Text in Playwright
All websites have images, and all images must have an alt-text. The reason it’s important to have alt-text is beyond the scope of this blog. Still, to provide a brief explanation, alt-text is important for accessibility, user experience, and image search SEO.
And Playwright has an efficient get_by_alt_text() locator to locate image and area elements using the alt-text attribute.
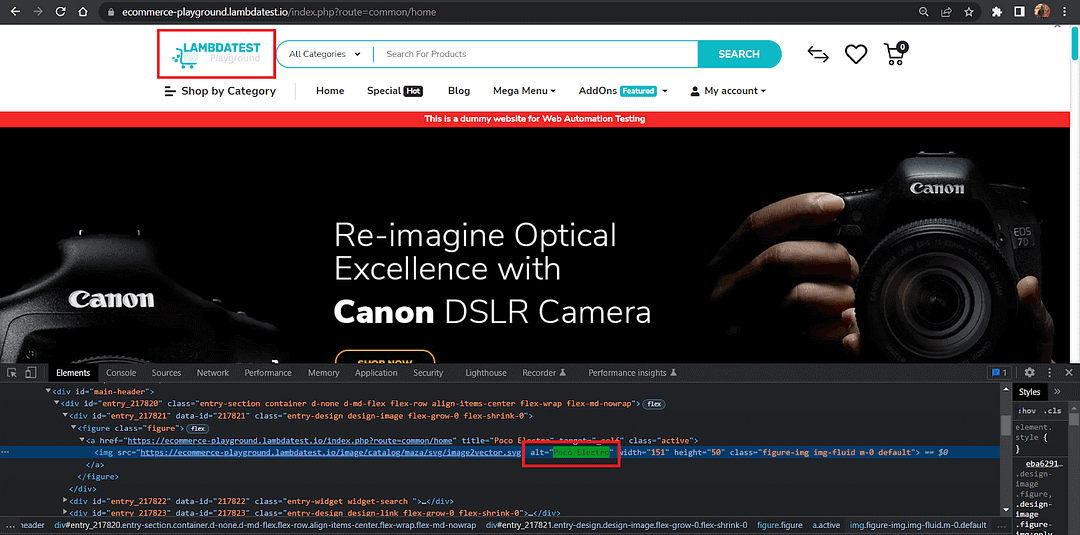
Below is the homepage of our demo website, and its logo can be used to demonstrate this Playwright locator effectively.
Test Scenario:
- The logo with alt-text=”Poco Electro” should be visible.
Sample Implementation:
# replace cloud_grid_page with local_grid_page while running on local
def test_logo_with_alt_text_should_be_visible(cloud_grid_page):
cloud_grid_page.goto(
"https://ecommerce-playground.lambdatest.io/index.php?route=common/home"
)
logo_locator = cloud_grid_page.get_by_alt_text(text="Poco Electro", exact=True).first
expect(logo_locator).to_be_visible()
Execution:

Code Walkthrough:
This is a rather simple one where we just get the alt-text from the Chrome Developer Tools and pass it onto the get_by_alt_text() locator.
Since there could be multiple uses of the same alt-text, we use the attribute first to narrow down our results to the first element.
The expect() then asserts if the selected element by the locator is visible.
Locating Elements by Title in Playwright
The HTML title attribute specifies additional information about an element. It is most commonly used on the < a > and < img > elements to provide a text description for screen readers and other assistive technologies. The text within the title attribute will typically appear as a tooltip when the mouse pointer hovers over the element.
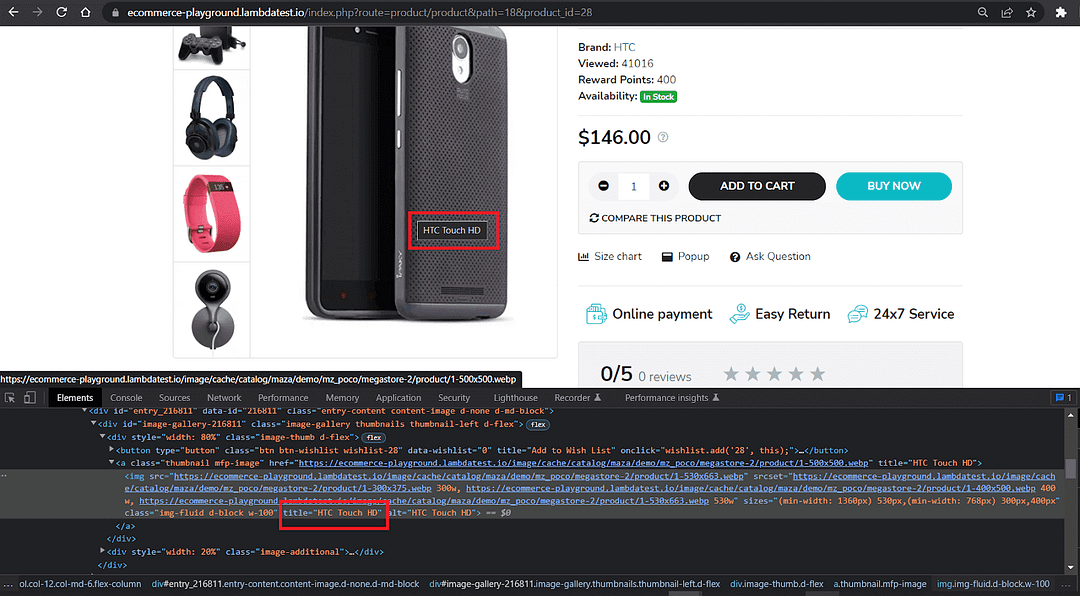
Here’s what the title attribute attached to the product image looks like from our demo website. We can use the get_by_title() Playwright locator to locate elements by title. It’s worth pointing out that our demo website uses the same title text for all images. Hence our locator will return more than one element(20).
Test Scenario:
- 20 elements with title=’HTC Touch HD’ should be present.
Sample Implementation:
# replace cloud_grid_page with local_grid_page while running on local
def test_display_count_of_all_elements_with_title_htc_touch_hd(cloud_grid_page):
cloud_grid_page.goto(
"https://ecommerce-playground.lambdatest.io/index.php?route=product/product&path=18&product_id=28"
)
alt_text_locator = cloud_grid_page.get_by_title(text=re.compile("htc touch hd", re.IGNORECASE))
expect(alt_text_locator).to_have_count(20)
Execution:

Code Walkthrough:
We open the product page, as usual, using the page.goto() method.
Next, we pass the title text we want to locate. Notice the use of the regex Python module to ignore the case.
The expect() assertion then verifies if the locator can detect all 20 elements.
Locating Elements by Test ID in Playwright
The Playwright locators, which we have seen so far, are based on HTML tags or attributes assigned to each element. However, the problem with this approach is that these tags, such as roles and attributes may change over time. If this happens, our tests will fail and need to be refactored to account for the changes.
To avoid this, test-ids are the most resilient way of testing a web application. Developers & QA’s can agree and define explicit test-ids for elements. Using these test-ids to query the elements ensures that our tests continue to work even if the role, text, or title of the elements changes.
Playwright provides the get_by_test_id() locator for locating elements by predefined test-ids. The default attribute that the get_by_test_id() locator looks for is data-testid. This behavior can be easily changed by setting a custom attribute to look for playwright.selectors.set_test_id_attribute(“data-pw”)
Playwright Locators using CSS and XPath
Playwright is fully flexible, and while the recommended locators should always be used, there might be scenarios of personal preferences for using CSS or XPath to locate elements. For such cases, we need to use the page.locator() that takes a selector describing how to find the element on the page.
Below are some examples of creating locators using the page.locator() method using CSS and XPath. We can omit the CSS and XPath prefixes, which will still work fine.
# Construction locators using CSS
page.locator("css=button").click()
page.locator("button").click()
page.locator( "#tsf > div:nth-child(2) > div.A8SBwf > div.RNNXgb > div > div.a4bIc > input").click()
# Construction locators Xpath
page.locator("xpath=//button").click()
page.locator("//button").click()
page.locator('//*[@id="tsf"]/div[2]/div[1]/div[1]/div/div[2]/input').click()
Shortcomings of CSS and XPath with Playwright
As evident from the examples above, CSS & XPath-based locators are tied to the Document Object Model (DOM) and become complicated to read, maintain, and unreliable very quickly. The DOM is subject to change, and hence the locators using them lead to non-resilient tests.
So, it’s best to develop tests using the recommended built-in locators such as role, text, or even better define explicit testing contracts using test ids.
Filtering and Chaining Playwright Locators
In modern software development, which strongly advocates code reuse and principles like D.R.Y (Don’t Repeat Yourself), there may be instances where we need to refine our results to pinpoint particular elements.
We ran into this scenario of broad/multiple matches even in the examples we saw for the recommended Playwright locators for locating elements by text in Playwright.
To handle this narrowing down of elements and to do it efficiently, Playwright has us covered by providing the ability to filter and chain locators.
Filtering vs Chaining
Filtering and Chaining are two methods that can be used to narrow down locating elements on a web page.
Filtering is used to narrow down the search for elements on a web page by specifying additional conditions that must be met. For example, you can use the filter(has_text=) to find an element containing a specific text piece.
Chaining is used to combine multiple locators in a single search. For example, you can use the get_by_text() and get_by_role() locators to find an element with a specific text and a specific role.
In summary, Filtering is used to refine a search further after an element has been located, while Chaining combines multiple search criteria to locate an element.
Filtering Playwright Locators
Playwright locators can be filtered by text. This search is case-insensitive and can also be done via regular expression. Playwright locators can also be filtered using another locator. For both cases, the method used is the locator.filter().
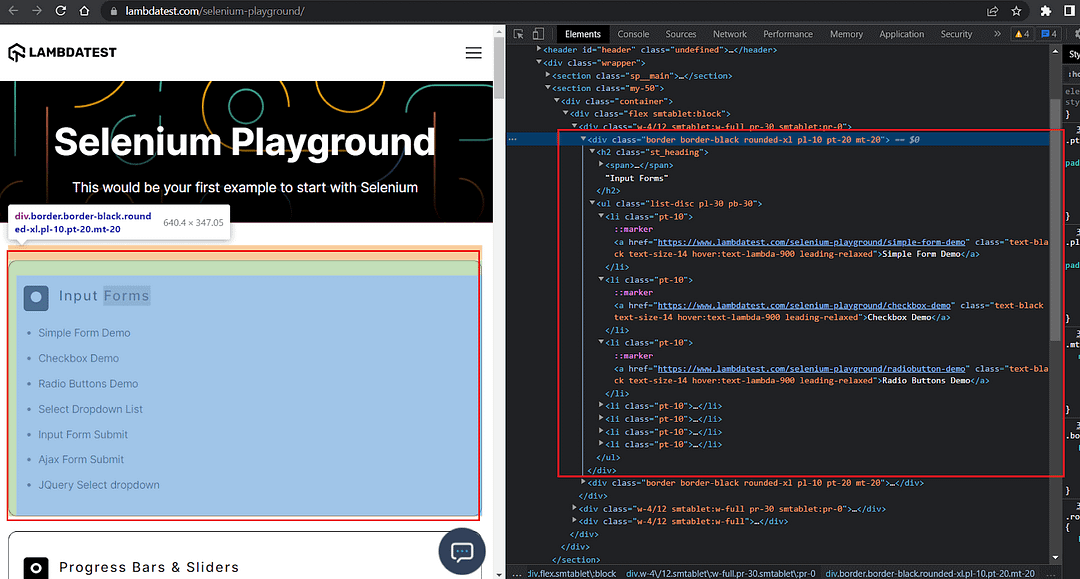
To understand filtering by another locator, let’s use a new demo website LambaTest Playground which has a nice block containing list items. Here’s the test scenario.
Test Scenario:
Locate the list containing Input Forms.
Filter & locate the Input Form Submit list item.
Sample Implementation:
# replace cloud_grid_page with local_grid_page while running on local
def test_locator_filter_by_another_locator(cloud_grid_page):
cloud_grid_page.goto(
"https://www.lambdatest.com/selenium-playground/"
)
base_locator = cloud_grid_page.get_by_role("listitem")
list_heading_locator = base_locator.filter(
has=cloud_grid_page.get_by_text(text=re.compile("input form submit", re.IGNORECASE))
)
expect(list_heading_locator).to_have_text('Input Form Submit')
Execution:

Code Walkthrough:
Upon inspection of the website using Chrome Developer Tools we see the presence of a list containing all the texts of the several different demos.
We form the base_locator using the get_by_role() locator and the ARIA role listitem.
This base_locator will contain all the lists on the page, and there are plenty.
So, we narrow down our lookup by calling the filter() method on our base_locator.
In the filter, we use the recommended get_by_text() locator and also make sure we handle case sensitivity using regular expressions by searching for the text ‘input for submit’, this filtered locator is called list_heading_locator.
On the filtered list_heading_locator we call the except() assertion and ensure we only have located the exact list item(for input form submit) that we intended to locate
Example: Filtering by Text
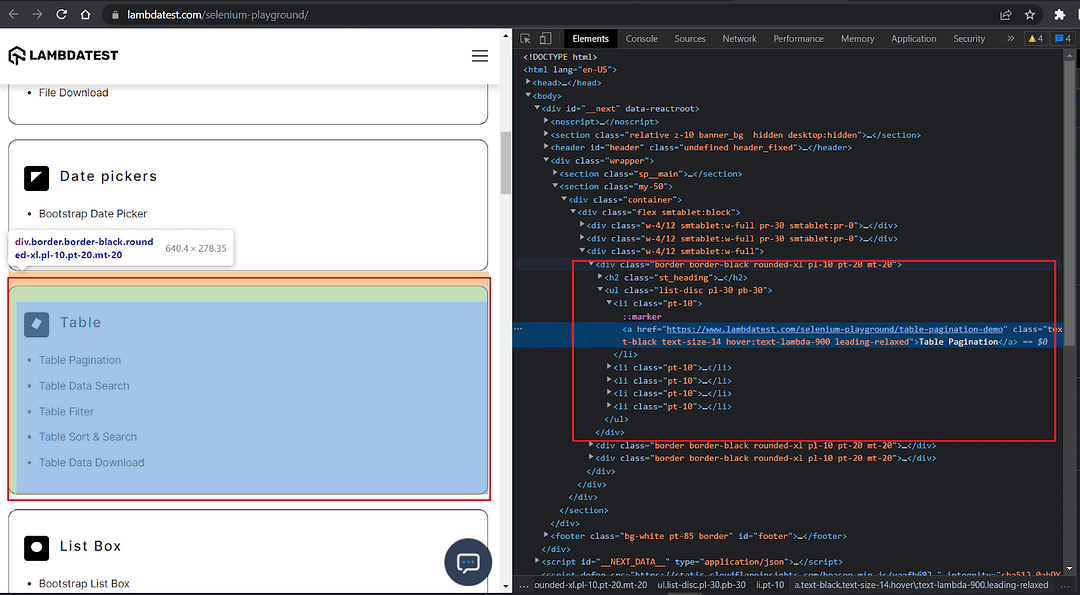
To understand filtering by text, let’s consider the same LambaTest Playground website but a different list, which has a lot of texts with the word ‘Table’.
Test Scenario:
Locate the list containing the Table.
The list has 5 items.
Sample Implementation:
# replace cloud_grid_page with local_grid_page while running on local
def test_locator_filter_by_text(cloud_grid_page):
cloud_grid_page.goto(
"https://www.lambdatest.com/selenium-playground/"
)
base_locator = cloud_grid_page.get_by_role("listitem")
table_list_locator = base_locator.filter(
has_text=re.compile("table", re.IGNORECASE)
)
expect(table_list_locator).to_have_count(5)
Execution:

Code Walkthrough:
The steps till we set up the base_locator remain the same as above test_locator_filter_by_another_locator() test.
From there, instead of using another locator-based filter, we filter based on text=’table’ by passing it to the filter() method.
The demo website inspection clearly shows the ‘Table’ list has 5 items, which is what we assert in the except().
That is all about filtering locators. In summary, they allow us to narrow down our search, we need to call the filter() method on a locator to apply to the filter, and the Filtering can be done either by text or using another locator, which is simple and efficient.
Chaining Playwright Locators
It’s not always possible for a single locator to locate the exact element on a webpage. In such scenarios, Chaining is the second method to narrow the search to a specific element by combining multiple locators.
Let’s revisit the same scenario we saw in the filter, i.e., locating an element from a list. Still, we will use locator Chaining to find the element instead of Filtering.
Test Scenario:
Locate the list containing Input Forms and narrow it down to Input Form Submit.
The Input Form Submit should be a link. The link href attribute should contain the words input-form-demo.
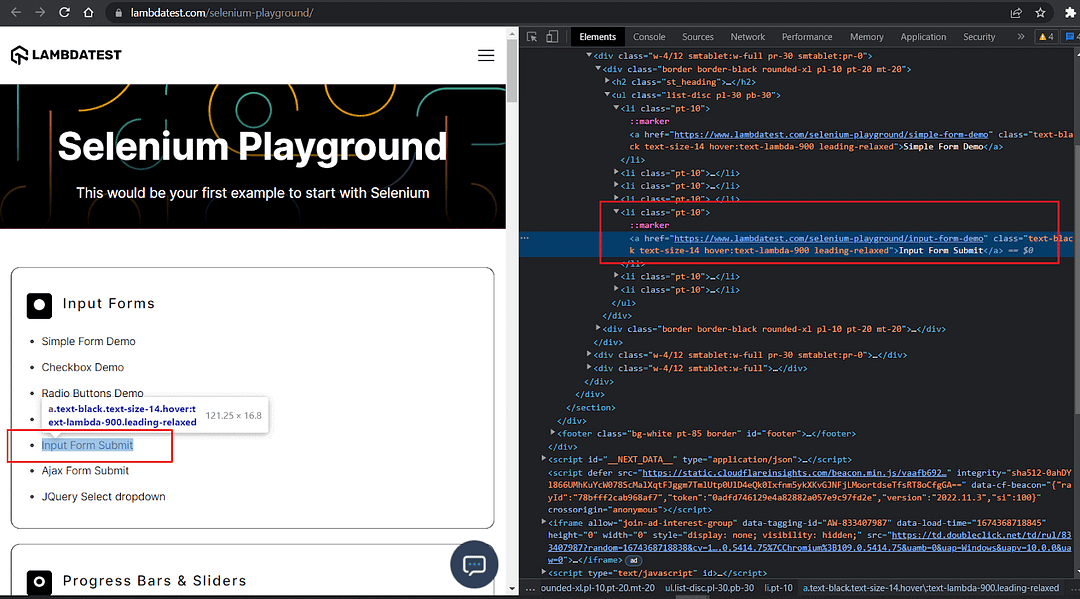
Sample Implementation:
# replace cloud_grid_page with local_grid_page while running on local
def test_locator_chaining(cloud_grid_page):
cloud_grid_page.goto(
"https://www.lambdatest.com/selenium-playground/"
)
input_form_locator = cloud_grid_page.get_by_role("listitem").get_by_text(text=re.compile("input form submit", re.IGNORECASE))
expect(input_form_locator).to_have_attribute(name="href", value=re.compile("input-form-demo", re.IGNORECASE))
Execution:

Code Walkthrough:
The DOM structure upon inspection clearly shows that we have a list & within each list is a link to the individual demo.
Hence, the first locator get_by_role(“listitem”) will locate all the lists on the page. There are approximately 6.
We then chain the get_by_text(text=re.compile(“input form submit”, re.IGNORECASE) to narrow down the result set to exactly match the input form submit list item.
Lastly, the except() assertion checks if the located element has a link, i.e., href attribute, and does a regular expression match to ensure the link contains certain keywords we know are necessary
So, that is about Chaining. Again, Filtering is used to refine a search further after an element has been located, while chaining combines multiple search criteria to locate an element.
Playwright Locator Methods
Throughout this Playwright locators blog, I have touched upon the various methods available in Playwright, such as filter(), first(), get_attribute(), etc. However, that is just the tip of the iceberg. There are numerous methods available to locate and perform desired actions using Playwright locators.
A complete list of available methods can be found in the official documentation. I strongly urge everyone to go over the Locators API documentation and explore the available methods of this super-powerful library.
Constructing Locators using Playwright’s Test Generator
We have been writing the tests manually by inspecting the DOM. But since we are talking about an automation framework, it only makes sense that Playwright has something which can assist and automate part of locating elements on a web page. Playwright has a powerful feature called the Test Generator, which can help you locate the elements and make it easier to write tests.
My only complaint about this feature is that it’s called Test Generator. The command to start it has the word codegen, and the subsequent generator that starts has the title Playwright Inspector. I sincerely wish Microsoft would fix this and agree on one name to simplify lives.
To start the Test Generator, we simply use the command shown below.
playwright codegen https://ecommerce-playground.lambdatest.io/
Feel free to replace the URL with the website you intend to write tests for.
Test Generator in Action
Here’s what the Test Generator looks like and the opened Chromium browser where we can perform the actions we want. Based on our actions, the Test Generator will generate the code for us.
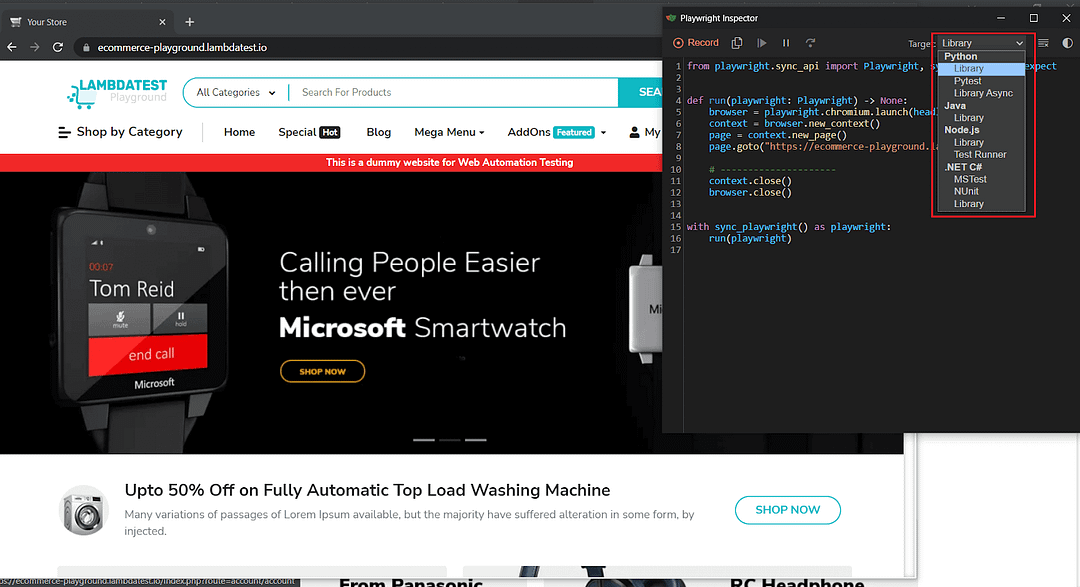
The cool thing about the Test Generator is that you can choose your intended language. For this blog, as you know, I have chosen Python, but Playwright allows you to choose whichever you wish from the drop-down highlighted in red.
Based on your selection, the Test Generator will write the code for us.
Let’s say we want to locate the search bar, type in mobile, and hit the search button. Here is the snapshot of the actions performed and the code the Test Generator was able to write for us with all the locators. We can then use these locators to run tests using the except() assertion.
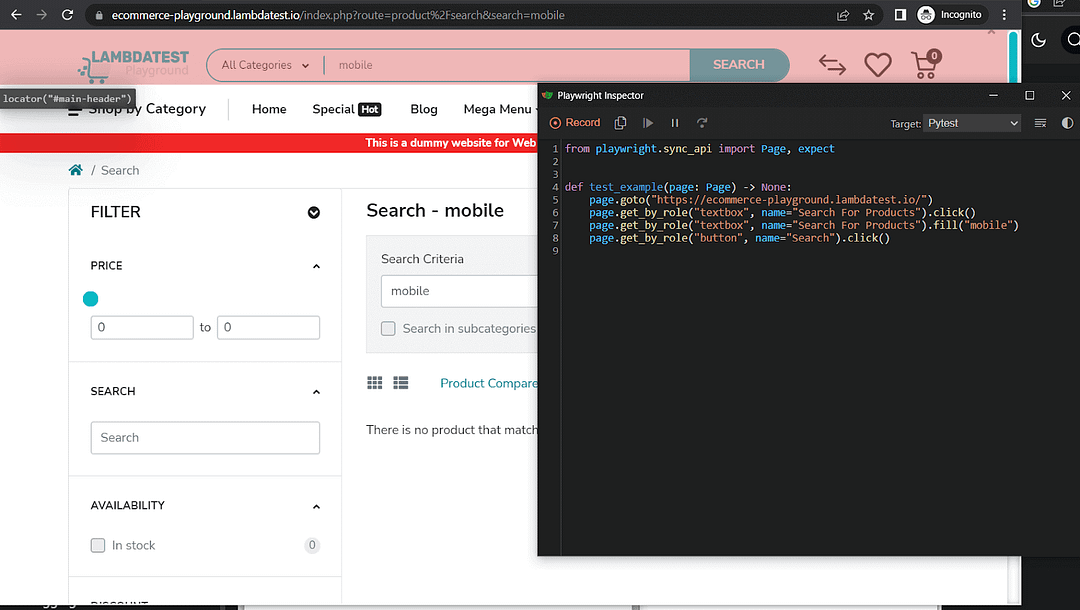
from playwright.sync_api import Page, expect
def test_example(page: Page) -> None:
page.goto("https://ecommerce-playground.lambdatest.io/")
page.get_by_role("textbox", name="Search For Products").click()
page.get_by_role("textbox", name="Search For Products").fill("mobile")
page.get_by_role("button", name="Search").click()
The Playwright Test Generator tool also comes with several built-in options to emulate devices, viewport sizes, color schemes, geolocation, timezone, etc.
Let’s see a quick demo of two of these features, and feel free to experiment with the other by referencing the official documentation.
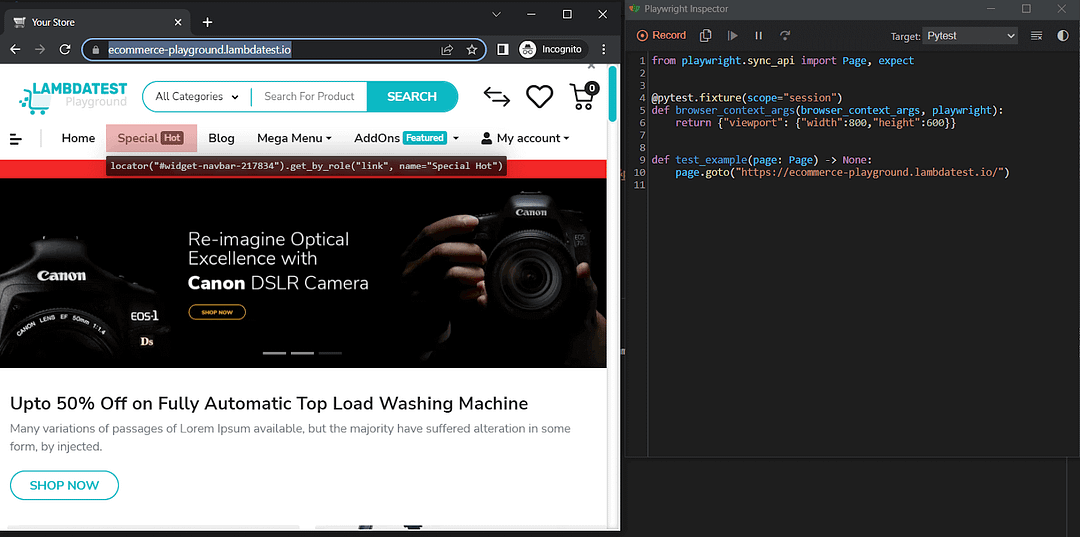
Emulate Viewport Size:
Notice how Playwright generates all the boiler-plate code for setting the viewport as a fixture.
playwright codegen --viewport-size=800,600 https://ecommerce-playground.lambdatest.io/
Emulate Devices:
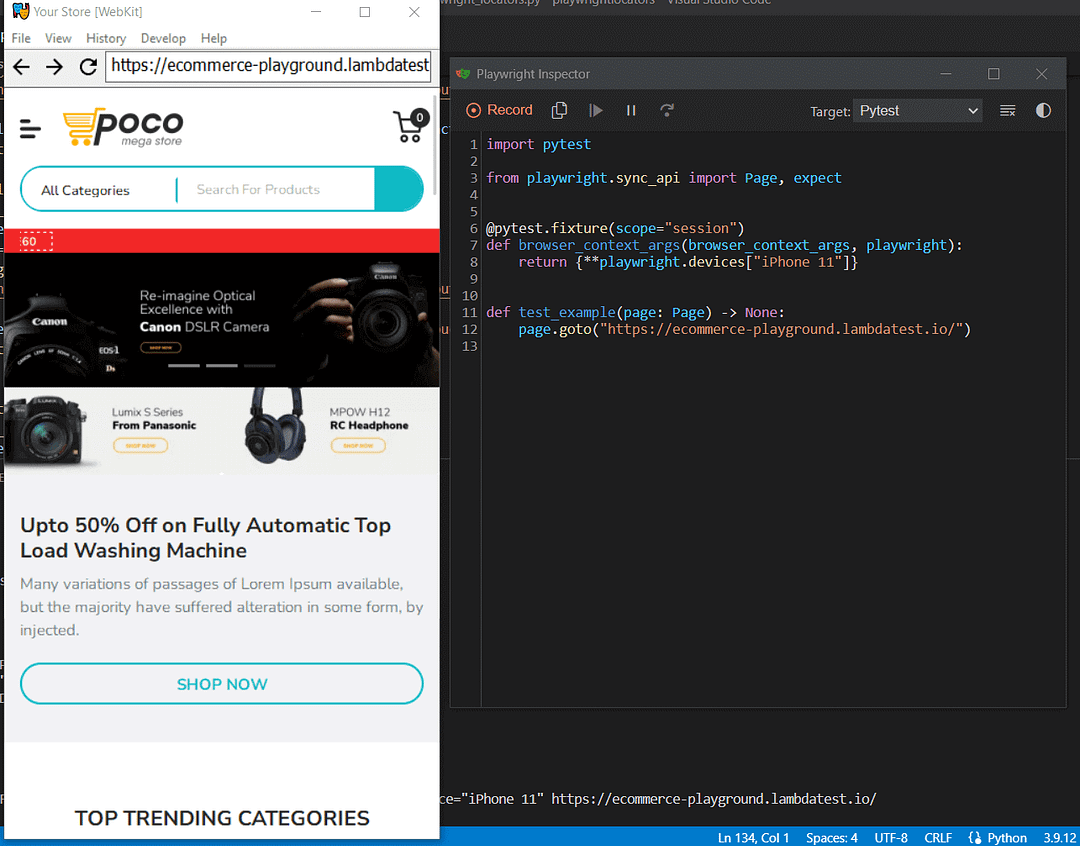
Notice how Playwright generates all the boiler-plate code for setting the device selected for testing as a fixture.
playwright codegen --device=”iPhone11” https://ecommerce-playground.lambdatest.io/
Want to demonstrate your expertise as a Playwright automation tester? LambdaTest’s Playwright 101 certification program is aimed at developers who want to showcase their proficiency in using Playwright for end-to-end testing of modern web applications.

Conclusion
That is it for this blog !!! In conclusion, Playwright locators are powerful tools that allow you to locate and interact with elements on a web page with the ability to locate elements by their attributes, role, text, label, alt-text, etc. Understanding the locators, Filtering, and Chaining and how to use them effectively is essential for writing efficient and reliable automated tests with Playwright.
The Playwright Test Generator tool can help you quickly and easily create boilerplate code for locating elements. The time and effort saved can be used to focus on more important tasks like writing resilient tests and improving coverage.
We have explored in great detail the world of Playwright Locators. Even with the level of detail, I’ve tried to cover, there’s much more to explore and experiment with, and I hope this blog serves as a solid foundation for that.